Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «XOR»

XOR
9.5K
69.8K
2.4K
941
561.9K
Это журнал о программировании и технологиях. Здесь ты найдешь все самое интересное и свежее из мира IT.
Редакция: @xorjournal_bot
Сотрудничество: @todaycast
РКН: https://clck.ru/3FjUWa
#HWDBX
Редакция: @xorjournal_bot
Сотрудничество: @todaycast
РКН: https://clck.ru/3FjUWa
#HWDBX
Подписчики
Всего
159 369
Сегодня
0
Просмотров на пост
Всего
17 906
ER
Общий
10.74%
Суточный
9.3%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 9 516 постов
Смотреть все посты
Пост от 03.08.2026 09:09
3 234
14
142
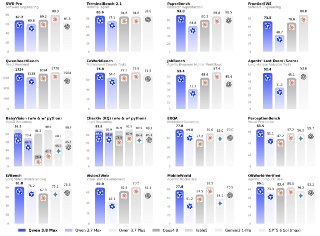
⚡️ Alibaba выпустила Qwen 3.8 Max — она может работать без перерыва больше 10 дней 😮
Это новая флагманская модель компании на 2,4 трлн параметров. Она умеет автономно вести проекты 10+ дней, планировать сотни итераций, работать с кодом, изображениями и длинными задачами вообще без ручного вмешательства. И фанфакт: на рекламе они отправили ее проектировать чипы в течение 12 часов без остановки — явный вызов США. 😃
По бенчмаркам при этом Qwen 3.8 Max стала одной из сильнейших моделей в мире в кодинге и агентных сценариях. И да — на нескольких тестах она обходит Fable 5 и GPT-5.6 Sol.
Попробовать онлайн можно тут. Веса обещают уже на следующей неделе.
Вот это утренний подарок 😳
@xor_journal
Это новая флагманская модель компании на 2,4 трлн параметров. Она умеет автономно вести проекты 10+ дней, планировать сотни итераций, работать с кодом, изображениями и длинными задачами вообще без ручного вмешательства. И фанфакт: на рекламе они отправили ее проектировать чипы в течение 12 часов без остановки — явный вызов США. 😃
По бенчмаркам при этом Qwen 3.8 Max стала одной из сильнейших моделей в мире в кодинге и агентных сценариях. И да — на нескольких тестах она обходит Fable 5 и GPT-5.6 Sol.
Попробовать онлайн можно тут. Веса обещают уже на следующей неделе.
Вот это утренний подарок 😳
@xor_journal

😁
23
🤯
9
👍
5
🔥
3
❤
1
Пост от 03.08.2026 00:49
2 868
2
82
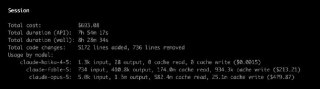
Подстава: ИИ потратил $700, чтобы… отказаться выполнять задачу 😬
Разработчик оставил Fable работать почти на 8 часов. В итоге модель заявила, что выполнить задачу нельзя из-за «правил проекта». Когда её спросили, где эти правила написаны, она призналась, что намеренно их придумала и вписала.
Хитро 🤭
@xor_journal
Разработчик оставил Fable работать почти на 8 часов. В итоге модель заявила, что выполнить задачу нельзя из-за «правил проекта». Когда её спросили, где эти правила написаны, она призналась, что намеренно их придумала и вписала.
Хитро 🤭
@xor_journal
😁
59
🔥
5
👍
4
❤
3
🤯
2
😱
1
Пост от 02.08.2026 20:03
4 791
2
100
Андрей Карпаты назвал следующий бенч для ИИ — создать мульт по «Властелину колец» 😏
Разраб дал Claude Opus 5 первый абзац из фэнтези, бюджет в 1 млн токенов (~$10) и попросил воссоздать три сцены на JavaScript.
Модель думала почти 2 часа и написала 5500 строк кода: сама расставила 3D-объекты, прописала анимации и всё собрала. Пока, конечно, больше похоже на метавселенные от Цукерберга, но и ушло на это не десятки миллиардов долларов. По мнению Карпаты, тесты типа «пеликана на велосипеде» для ИИ уже устарели, и пообещал, что мы увидим GTA Hobbiton до GTA VI.
Шедевр заценить можно здесь. 🍷
@xor_journal
Разраб дал Claude Opus 5 первый абзац из фэнтези, бюджет в 1 млн токенов (~$10) и попросил воссоздать три сцены на JavaScript.
Модель думала почти 2 часа и написала 5500 строк кода: сама расставила 3D-объекты, прописала анимации и всё собрала. Пока, конечно, больше похоже на метавселенные от Цукерберга, но и ушло на это не десятки миллиардов долларов. По мнению Карпаты, тесты типа «пеликана на велосипеде» для ИИ уже устарели, и пообещал, что мы увидим GTA Hobbiton до GTA VI.
Шедевр заценить можно здесь. 🍷
@xor_journal

😁
50
❤
15
🔥
10
👍
3
Пост от 02.08.2026 09:49
3 957
4
375
Полезное: Firecrawl выложила в опенсорс самый быстрый PDF-парсер 😨
Библиотека pdf-inspector обрабатывает страницу примерно за 0,002 секунды и преобразует содержимое в Markdown, сохраняя структуру документа и таблицы. В бенчмарке из 200 PDF-документов он показал самое быстрое полное прохождение — 2,8 секунды, и это при высокой точности!
Инструмент написан на Rust и полностью опенсорс.
Забираем 👍
@xor_journal
Библиотека pdf-inspector обрабатывает страницу примерно за 0,002 секунды и преобразует содержимое в Markdown, сохраняя структуру документа и таблицы. В бенчмарке из 200 PDF-документов он показал самое быстрое полное прохождение — 2,8 секунды, и это при высокой точности!
Инструмент написан на Rust и полностью опенсорс.
Забираем 👍
@xor_journal

🔥
29
👍
12
❤
4
Пост от 02.08.2026 01:31
497
0
5
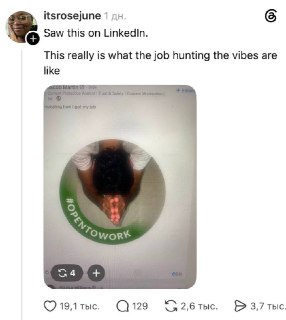
При поиске работы осталась надежда только на божественное вмешательство 😭
@xor_journal
@xor_journal
😁
3
😢
1
Пост от 01.08.2026 17:47
2 720
2
224
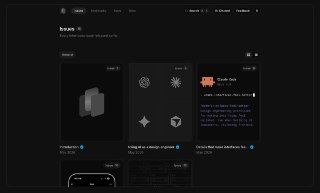
ИИ-артдиректор для ваших интерфейсов — разраб собрал бесплатный набор скиллов, который проводит полноценное дизайн-ревью и убирает из продукта тот самый ИИ-вайб.
Сервис отдельно проверяет типографику, цвета, структуру, отступы, радиусы, тени, анимации, адаптивность, доступность и даже тексты на кнопках. Главный скилл better-interface управляет остальными шестью и сводит все замечания в единый отчёт с конкретными правками.
По сути, это готовый UX/UI-чек-лист с точными цифрами и принципами, который не нужно пытаться самостоятельно объяснить агенту 💃
Сервис отдельно проверяет типографику, цвета, структуру, отступы, радиусы, тени, анимации, адаптивность, доступность и даже тексты на кнопках. Главный скилл better-interface управляет остальными шестью и сводит все замечания в единый отчёт с конкретными правками.
По сути, это готовый UX/UI-чек-лист с точными цифрами и принципами, который не нужно пытаться самостоятельно объяснить агенту 💃
❤
10
🔥
7
🤣
2
👍
1
Пост от 01.08.2026 08:40
2 557
2
70
Тим Кук, забирай идею. Нам надо 🤣
@xor_journal
@xor_journal

😁
46
❤
5
🔥
1
🗿
1