Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «Системный администратор - Сетевые технологии - Компьютерная помощь»

Системный администратор - Сетевые технологии - Компьютерная помощь
8.8K
1.8K
99
23
36.6K
Канал для системных администраторов или те кто работает в ИТ сфере.
📚КНИГИ ПО
💠Cisco systems
💠Mikrotik
💠VoIP
💠Linux
💠 Windows server
💠 Сетевые технологии
📽Видеоуроки
🤝Поддержка
Наша группа: @SySAD
Feedback bot: @SySADbot
📚КНИГИ ПО
💠Cisco systems
💠Mikrotik
💠VoIP
💠Linux
💠 Windows server
💠 Сетевые технологии
📽Видеоуроки
🤝Поддержка
Наша группа: @SySAD
Feedback bot: @SySADbot
Подписчики
Всего
8 694
Сегодня
0
Просмотров на пост
Всего
1 029
ER
Общий
10.38%
Суточный
8.8%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 8 818 постов
Смотреть все посты
Пост от 03.08.2026 10:34
305
0
4
@sysadmin1

👍
3
Пост от 03.08.2026 07:33
146
0
1
@sysadmin1

👍
1
🎉
1
Пост от 03.08.2026 07:30
157
0
0
Основные шаблоны проектирования в системном дизайне
Знать CQRS, Event Sourcing и Saga недостаточно, чтобы правильно применять эти шаблоны в реальной системе. Каждый из них решает архитектурную проблему, но одновременно увеличивает сложность разработки, эксплуатации и поддержки. Если выбирать паттерн только потому, что он популярен или используется в высоконагруженных проектах, можно получить архитектуру, сложнее самой задачи.
На открытом уроке 24 августа в 20:00 в OTUS разберём ключевые шаблоны системного дизайна: CQRS, Event Sourcing и Saga Pattern. Рассмотрим, какие проблемы они решают, в каких системах действительно нужны и какие новые ограничения создают. На практических примерах посмотрим, как эти подходы применяются в высоконагруженных сервисах, событийных системах и процессах с распределёнными транзакциями.
Узнать больше
#реклама 16+
otus.ru
О рекламодателе
Знать CQRS, Event Sourcing и Saga недостаточно, чтобы правильно применять эти шаблоны в реальной системе. Каждый из них решает архитектурную проблему, но одновременно увеличивает сложность разработки, эксплуатации и поддержки. Если выбирать паттерн только потому, что он популярен или используется в высоконагруженных проектах, можно получить архитектуру, сложнее самой задачи.
На открытом уроке 24 августа в 20:00 в OTUS разберём ключевые шаблоны системного дизайна: CQRS, Event Sourcing и Saga Pattern. Рассмотрим, какие проблемы они решают, в каких системах действительно нужны и какие новые ограничения создают. На практических примерах посмотрим, как эти подходы применяются в высоконагруженных сервисах, событийных системах и процессах с распределёнными транзакциями.
Узнать больше
#реклама 16+
otus.ru
О рекламодателе

🎉
1
Пост от 03.08.2026 07:01
252
0
2
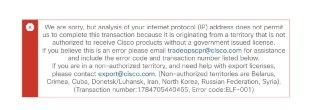
#Компьютер #Computer
@sysadmin1
@sysadmin1

❤
1
👍
1
Пост от 03.08.2026 04:39
131
0
3
Классика... золотой стандарт малого бизнеса
@sysadmin1
@sysadmin1

👍
1
Пост от 02.08.2026 20:09
157
3
1
Пост от 02.08.2026 20:09
388
0
0
Газовая варочная панель FS 66 B KUPPERSBERG
Надежная варочная панель от KUPPERSBERG — официальный сайт производителя.
Узнать больше
#реклама
kuppersberg.ru
О рекламодателе
Надежная варочная панель от KUPPERSBERG — официальный сайт производителя.
Узнать больше
#реклама
kuppersberg.ru
О рекламодателе
