Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «Наташа Косинова. Варю айти СУП»

Наташа Косинова. Варю айти СУП
792
4.4K
29
5
7.0K
Написать мне @tasha_kvitka
Канал про ИТ, системный анализ, проектирование ИТ-систем, карьерный рост, менторство.
Делаю сложное - простым!
Мои услуги: https://sup.expert/
Канал про ИТ, системный анализ, проектирование ИТ-систем, карьерный рост, менторство.
Делаю сложное - простым!
Мои услуги: https://sup.expert/
Подписчики
Всего
2 589
Сегодня
0
Просмотров на пост
Всего
193
ER
Общий
7.26%
Суточный
5.3%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 792 постов
Смотреть все посты
Пост от 27.07.2026 13:02
60
3
3
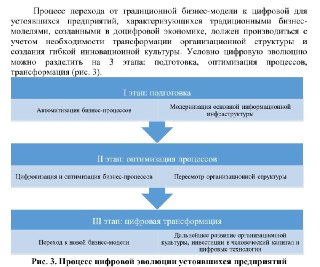
⌛С места в карьер - постоянно крутится, эта фраза в имея голове, когда говорят про внедрение ИИ в компаниях, где "голое поле" в плане автоматизации...
Меня удивляет, то как наш бизнес наивно думает, что вот есть ручные операции, и давайте сразу их заменим на ИИ. Для меня ИИ это технология, которая по сути новый этап цифровизации. И до ИИ нужно дорасти.
Есть этапы цифровизации организации, картинку нашла из научной статьи. И вместе с этими этапами происходит зрелость процессов, сотрудников и процессы перестройки.
И вот представьте, есть ручные операции и сразу их меняем на ИИ. Да, вставим шаги контроля, валидацию, будем контролировать ИИ.
Напоминает мне такие штуки, когда на гос проектах делали большую кнопку, чтобы как-то оставить сотрудников и дать им работу, и иллюзию контроля.
При этом вспомним закон конвея, который нам говорит, что ландшафт ИТ отражает коммуникацию в организации. То есть, если все привыкли звонить по любому чиху диспетчеру, то оно также и будет происходить. И мы получаем некий бардак, нужно как-то встроить ИИ, с места в карьер, и сразу на процессах, которые не зрелые и никогда не были автоматизированны, и тем более не проходили этап оптимизации.
Как же я "люблю", громкие слова, наподобие "давайте сразу при автоматизации/цифровизации ещё и оптимизацию процессов проводить".
Это равносильно тому, что вы на антибиотиках и ещё параллельно решили бегать по утрам и сидеть на диете для похудения.
Я за естественное развитие, потому что резкое внедрение, также резкое отторжение вызывает, и сильно ломает и людей, и то что сложилось годами.
Никогда не прыгали с вышки в воду, и полезли сразу на 10 метров.
#иишка #внедрение #мысливслух #автоматизация #цифровизация
Меня удивляет, то как наш бизнес наивно думает, что вот есть ручные операции, и давайте сразу их заменим на ИИ. Для меня ИИ это технология, которая по сути новый этап цифровизации. И до ИИ нужно дорасти.
Есть этапы цифровизации организации, картинку нашла из научной статьи. И вместе с этими этапами происходит зрелость процессов, сотрудников и процессы перестройки.
И вот представьте, есть ручные операции и сразу их меняем на ИИ. Да, вставим шаги контроля, валидацию, будем контролировать ИИ.
Напоминает мне такие штуки, когда на гос проектах делали большую кнопку, чтобы как-то оставить сотрудников и дать им работу, и иллюзию контроля.
При этом вспомним закон конвея, который нам говорит, что ландшафт ИТ отражает коммуникацию в организации. То есть, если все привыкли звонить по любому чиху диспетчеру, то оно также и будет происходить. И мы получаем некий бардак, нужно как-то встроить ИИ, с места в карьер, и сразу на процессах, которые не зрелые и никогда не были автоматизированны, и тем более не проходили этап оптимизации.
Как же я "люблю", громкие слова, наподобие "давайте сразу при автоматизации/цифровизации ещё и оптимизацию процессов проводить".
Это равносильно тому, что вы на антибиотиках и ещё параллельно решили бегать по утрам и сидеть на диете для похудения.
Я за естественное развитие, потому что резкое внедрение, также резкое отторжение вызывает, и сильно ломает и людей, и то что сложилось годами.
Никогда не прыгали с вышки в воду, и полезли сразу на 10 метров.
#иишка #внедрение #мысливслух #автоматизация #цифровизация
👍
1
Пост от 22.07.2026 14:48
46
0
1
Вкатывание в новый проект
Каждый раз говорю, о том, что новый проект, новая предметная область, всё новое это стресс #капитаночевидность и тут главное это понимать, понимать свои границы ответственности, готовиться к рабочими встречам, но сама наступаю на те же грабли))
Тут конечно первое правило - назвать положение дел своими словами.
А то получится, как в менторской сессии с аналитиком: "мне кажется я плохой аналитик и что-то делаю не так", а результат этого вывода, это то, что на уровне менеджеров неразбериха, и до аналитика она дошла и исказилась.
Какие тут могу выводы сделать:
✔️1.Понимать, что высокая степень неопределённости - это высокий стресс и иметь в запасе список действий, которые дают энергию и стресс снижают (у кого-то это прогулка с собакой, выпить кофе, позвонить другу, всё что угодно и что укладывается в 15 минут, когда в стрессе мозг отрубает и лучше заранее написать список).
✔️2.У меня есть такая черта, что я долго присматриваюсь к новым людям. Это не значит, что я не хочу общаться, или как-то ухожу в свой домик, это значит, что мне нужно какие сделать выводы для себя и стратегию поведения выработать. Особенно это видно в походах, сплавах, где ты условно в одной лодке с людьми.
✔️3.Стресс имеет свойство копиться, лучше его сливать сразу. Спорт, как по мне, лучшее лекарство. Мне помогает мелкая моторика. В команде для этого как раз ретроспектива нужна, но тут тоже отдельная задача создать пространство, где можно высказывать открыто. Это не всегда возможно.
✔️4.Карта заинтересованных лиц, оргструктуры, понимание того, кто на каком уровне принимает решения и влияет на это решение. Оно чаще всего в голове есть, но когда начинает строить диаграмму появляются нюансы, а может быть даже новые персонажи.
✔️5.У меня из моего жизненного опыта есть прекрасная история, когда всю нашу команду отправили к новому заказчику, как команду тестирования. Но никто нам не сказал, что нам нужно сыграть роли тестировщиков! Мы хотели чуть ли не в этот день написать заявление на увольнение. И все хором сказали заказчику, что если нас возьмут как тестировщиков мы уйдём. Провал менеджеров был грандиозный. К любой встрече с заказчиком нужно готовиться (понимать, кто будет, что будем обсуждать, что можно говорить, что нельзя, какая есть субординация, и обязательно нужна визуализация - списки вопросов, холст, картинки, диаграммы, mind maps всё подойдёт, на ночных встречах я всегда себе говорю - просто возьми фломастер и пиши, рисуй, чтобы не было страха белого листа).
✔️6.Любые эмоции - это нормально, это рабочий момент. Любые недопонимания, косяки, это тоже нормально, невозможно всегда быть идеалом. Тут конечно приходит синдром самозванца, особенно когда включается "ты же профессионал, значит может, значит ожидания от тебя завышенные".
✔️7.Очень важный пункт - присваивать достижения, результаты, оценивать промежуточное качество, понимая что было на входе и какой сделан вклад. Даже если об этом никто не говорит. Может сказать ментор, или коллега с бОльшим опытом. Если спрашивать у коллег, то тоже нужно понимать у кого и как справиться с критикой, если она будет и понять насколько она адекватная. Всю ситуацию своего состояния знаете только вы.
Полезные ссылки по теме:
🎙️Подкасты как погружаться в предметную область:
1. Часть про границы "картины мира"
2. Часть про модель предметки
3. Часть про психологию изучения нового
4. Часть про картинки
5. Часть про внешние источники
---------
📹Вебинар по предметке - rutube
---------
Другие посты по теме:
1. Кто такой стейкхолдер. Карта заинтересованных лиц.
2. Конус неопределённости.
3. Диаграмма эффект Даннинга-Крюгера.
4. Эффект Бандуры изучения нового.
5. Метод поедания сыра мышью
#предметнаяобласть #новыйпроект #мойопыт #softskills
Каждый раз говорю, о том, что новый проект, новая предметная область, всё новое это стресс #капитаночевидность и тут главное это понимать, понимать свои границы ответственности, готовиться к рабочими встречам, но сама наступаю на те же грабли))
Тут конечно первое правило - назвать положение дел своими словами.
А то получится, как в менторской сессии с аналитиком: "мне кажется я плохой аналитик и что-то делаю не так", а результат этого вывода, это то, что на уровне менеджеров неразбериха, и до аналитика она дошла и исказилась.
Какие тут могу выводы сделать:
✔️1.Понимать, что высокая степень неопределённости - это высокий стресс и иметь в запасе список действий, которые дают энергию и стресс снижают (у кого-то это прогулка с собакой, выпить кофе, позвонить другу, всё что угодно и что укладывается в 15 минут, когда в стрессе мозг отрубает и лучше заранее написать список).
✔️2.У меня есть такая черта, что я долго присматриваюсь к новым людям. Это не значит, что я не хочу общаться, или как-то ухожу в свой домик, это значит, что мне нужно какие сделать выводы для себя и стратегию поведения выработать. Особенно это видно в походах, сплавах, где ты условно в одной лодке с людьми.
✔️3.Стресс имеет свойство копиться, лучше его сливать сразу. Спорт, как по мне, лучшее лекарство. Мне помогает мелкая моторика. В команде для этого как раз ретроспектива нужна, но тут тоже отдельная задача создать пространство, где можно высказывать открыто. Это не всегда возможно.
✔️4.Карта заинтересованных лиц, оргструктуры, понимание того, кто на каком уровне принимает решения и влияет на это решение. Оно чаще всего в голове есть, но когда начинает строить диаграмму появляются нюансы, а может быть даже новые персонажи.
✔️5.У меня из моего жизненного опыта есть прекрасная история, когда всю нашу команду отправили к новому заказчику, как команду тестирования. Но никто нам не сказал, что нам нужно сыграть роли тестировщиков! Мы хотели чуть ли не в этот день написать заявление на увольнение. И все хором сказали заказчику, что если нас возьмут как тестировщиков мы уйдём. Провал менеджеров был грандиозный. К любой встрече с заказчиком нужно готовиться (понимать, кто будет, что будем обсуждать, что можно говорить, что нельзя, какая есть субординация, и обязательно нужна визуализация - списки вопросов, холст, картинки, диаграммы, mind maps всё подойдёт, на ночных встречах я всегда себе говорю - просто возьми фломастер и пиши, рисуй, чтобы не было страха белого листа).
✔️6.Любые эмоции - это нормально, это рабочий момент. Любые недопонимания, косяки, это тоже нормально, невозможно всегда быть идеалом. Тут конечно приходит синдром самозванца, особенно когда включается "ты же профессионал, значит может, значит ожидания от тебя завышенные".
✔️7.Очень важный пункт - присваивать достижения, результаты, оценивать промежуточное качество, понимая что было на входе и какой сделан вклад. Даже если об этом никто не говорит. Может сказать ментор, или коллега с бОльшим опытом. Если спрашивать у коллег, то тоже нужно понимать у кого и как справиться с критикой, если она будет и понять насколько она адекватная. Всю ситуацию своего состояния знаете только вы.
Полезные ссылки по теме:
🎙️Подкасты как погружаться в предметную область:
1. Часть про границы "картины мира"
2. Часть про модель предметки
3. Часть про психологию изучения нового
4. Часть про картинки
5. Часть про внешние источники
---------
📹Вебинар по предметке - rutube
---------
Другие посты по теме:
1. Кто такой стейкхолдер. Карта заинтересованных лиц.
2. Конус неопределённости.
3. Диаграмма эффект Даннинга-Крюгера.
4. Эффект Бандуры изучения нового.
5. Метод поедания сыра мышью
#предметнаяобласть #новыйпроект #мойопыт #softskills
❤
1
Пост от 20.07.2026 17:29
83
0
1
Мы здесь регулярно говорим про микроменеджмент. Но что, если эта тема не только про доверие, а в первую очередь, про внимание руководителя?
Когда вокруг всё меняется, именно внимание становится самым дефицитным управленческим ресурсом. И если оно начинает уходить на постоянные проверки, перепоручения и контроль каждой детали, у руководителя просто не остается ресурса на стратегию, принятие решений и развитие команды.
В июне состоялся прямой эфир «Как делегировать, когда всё вокруг меняется: доверие, контроль и результат в нестабильные периоды». Тему поддержали:
🎙️ Дмитрий Безуглый - эксперт по стратегическому управлению продуктами и командами с опытом более 20 лет, основатель школы стратегического управления Master Strategy, консультант Яндекс Практикума, Авито, Wargaming, Acronis, Лаборатории Касперского, Т Банка, Сбера, ВТБ.
🎙️ Наталья Косинова - системный аналитик с 20+ лет опыта, прошла путь от технического писателя до руководителя отдела анализа, управляла командой из 25 аналитиков, работала на проектах Билайн, МТС, Тинькофф Страхование, Росгвардии, Утконоса, а также в сфере энергетики и промышленности.
Обсудили важное
➡️ Делегирование задач в условиях изменений и нестабильности.
➡️ Границу между делегированием и микроменеджментом.
➡️ Почему в кризис руководители переходят к чрезмерному контролю.
➡️ Доверие в команде и способы его выстраивания.
➡️ Влияние уровня зрелости сотрудников на стиль управления.
➡️ Выгорание руководителя и команды.
💡 А главное - разобрали реальный кейс слушательницы эфира о делегировании на нескольких уровнях управления
Один из главных выводов, который для меня прозвучал в этом разговоре: делегирование — это не отказ от контроля. Это способность удерживать внимание на своем уровне управления.
Пока руководитель погружен в операционные мелочи, стратегия остается без внимания. А значит, самые важные решения оказываются отложенными именно в тот момент, когда они нужны больше всего.
Включайте на удобной платформе и смотрите прямо сейчас:
📺 YouTube
📺 Рутуб
📱 LinkedIn
С вас — репост, с меня — новые гости и новые крутые интервью 😉
Когда вокруг всё меняется, именно внимание становится самым дефицитным управленческим ресурсом. И если оно начинает уходить на постоянные проверки, перепоручения и контроль каждой детали, у руководителя просто не остается ресурса на стратегию, принятие решений и развитие команды.
В июне состоялся прямой эфир «Как делегировать, когда всё вокруг меняется: доверие, контроль и результат в нестабильные периоды». Тему поддержали:
🎙️ Дмитрий Безуглый - эксперт по стратегическому управлению продуктами и командами с опытом более 20 лет, основатель школы стратегического управления Master Strategy, консультант Яндекс Практикума, Авито, Wargaming, Acronis, Лаборатории Касперского, Т Банка, Сбера, ВТБ.
🎙️ Наталья Косинова - системный аналитик с 20+ лет опыта, прошла путь от технического писателя до руководителя отдела анализа, управляла командой из 25 аналитиков, работала на проектах Билайн, МТС, Тинькофф Страхование, Росгвардии, Утконоса, а также в сфере энергетики и промышленности.
Обсудили важное
➡️ Делегирование задач в условиях изменений и нестабильности.
➡️ Границу между делегированием и микроменеджментом.
➡️ Почему в кризис руководители переходят к чрезмерному контролю.
➡️ Доверие в команде и способы его выстраивания.
➡️ Влияние уровня зрелости сотрудников на стиль управления.
➡️ Выгорание руководителя и команды.
💡 А главное - разобрали реальный кейс слушательницы эфира о делегировании на нескольких уровнях управления
Один из главных выводов, который для меня прозвучал в этом разговоре: делегирование — это не отказ от контроля. Это способность удерживать внимание на своем уровне управления.
Пока руководитель погружен в операционные мелочи, стратегия остается без внимания. А значит, самые важные решения оказываются отложенными именно в тот момент, когда они нужны больше всего.
Включайте на удобной платформе и смотрите прямо сейчас:
📺 YouTube
📺 Рутуб
С вас — репост, с меня — новые гости и новые крутые интервью 😉

❤
1
Пост от 20.07.2026 17:29
55
0
0
Лена вспомнила про наш прямой эфир, решила с вами поделиться, вдруг будет в тему 😎
Пост от 16.07.2026 17:34
144
4
0
Коммуникация
Очень много всего разного есть, и я решила посчитать какое количество у меня мессанджеров и способов коммуникацией.
Начнём с того, что:
Телега жива и больше всего мне нравится)
Дальше, сорян, меня нет в макс, так что появились альтернативы, где я общаюсь - VK, express, на проекте, куда я вышла работать, был выбран - mattermost, с друзьями я много, где общаюсь, тут нельзяграм, обычные звонки, смски. Забугорные человеки - вотсап, пара человек точно.
Промежуточный итог: 7
Что ещё?)
Аааа, видео конференции!
Тут лидер у меня пока телемост, за ним идёт неправославный зум, гугл мит иногда, на работе dion, очень мало было звонков в МТС линк, кстати контур мне очень нравится, жаль, что он думает больше про корпорации, если есть возможность, я всегда за контур!
А ну куда же без сбер.джазз 😂
Выходит тоже 7.
Ох, если выстроить мою карту коммуникаций, и способов общения, можно прифигеть. Фактически способ общения исходит из того, с кем общаешься и где этот человек находится. Просто уже знаю, кто на что реагирует. Но городской телефон я убрала 😂
Для полноты нужен скайп и аська, если бы они были живы, чтобы они развивались, надо было бы там общаться... Говорят скайп у кого-то жив ещё.
Итого: 14, и добавлю ещё обычную электронную почту - и будет 15!
У кого список больше❓
Делитесь)
P. S. Ждём решений или ИИ-агентов, которые бы это всё многобразие собирали и синхронизировали
#коммуникация
Очень много всего разного есть, и я решила посчитать какое количество у меня мессанджеров и способов коммуникацией.
Начнём с того, что:
Телега жива и больше всего мне нравится)
Дальше, сорян, меня нет в макс, так что появились альтернативы, где я общаюсь - VK, express, на проекте, куда я вышла работать, был выбран - mattermost, с друзьями я много, где общаюсь, тут нельзяграм, обычные звонки, смски. Забугорные человеки - вотсап, пара человек точно.
Промежуточный итог: 7
Что ещё?)
Аааа, видео конференции!
Тут лидер у меня пока телемост, за ним идёт неправославный зум, гугл мит иногда, на работе dion, очень мало было звонков в МТС линк, кстати контур мне очень нравится, жаль, что он думает больше про корпорации, если есть возможность, я всегда за контур!
А ну куда же без сбер.джазз 😂
Выходит тоже 7.
Ох, если выстроить мою карту коммуникаций, и способов общения, можно прифигеть. Фактически способ общения исходит из того, с кем общаешься и где этот человек находится. Просто уже знаю, кто на что реагирует. Но городской телефон я убрала 😂
Для полноты нужен скайп и аська, если бы они были живы, чтобы они развивались, надо было бы там общаться... Говорят скайп у кого-то жив ещё.
Итого: 14, и добавлю ещё обычную электронную почту - и будет 15!
У кого список больше❓
Делитесь)
P. S. Ждём решений или ИИ-агентов, которые бы это всё многобразие собирали и синхронизировали
#коммуникация
👍
3
🔥
1
🏆
1
Пост от 14.07.2026 12:03
60
0
0
Напишу свой вариант ответа, по ситуации, что описала выше.
Спасибо за активность, непростая задача, и я вижу, что потребовалось время осознать, что я вообще тут намоделировала 😂
Пишу по пунктам алгоритм анализа, начиная с бизнес уровня:
1. Выяснить политический контекст ситуации. О чем договорились уже. Кто за что отвечает и какие есть, и есть ли, рычаги влияния. Тут по-хорошему карту заинтересованных лиц описать. И некий приоритет, кто в первом приоритете влияния.
2.Понять, что есть на нашей территории, и что мы делаем в рамках проекта. Иногда реально сложно понять, мы работаем над проектом или продуктом. Часто руководители говорят о продукте, но фактически его нет и идёт работа по проекту. У меня есть статья про разницу проекта и продукта, можно вот тут почитать.
3.Раз уже есть продукт или подобие продукта, а документы от заказчика противоречивые, то стоит изучить существующий вариант, по нему зафиксировать некий концепт. Проще всего предложить заказчику, то что уже есть.
4.Поговорить с коллегами, кто уже общался с заказчиком. По этим договорённостям составить тоже некий концепт. Я люблю графы, поэтому составляю mind maps по проектам.
5.Понять насколько то, что хочет заказчик или якобы хочет, отличается от текущей версии реализации (совместить один граф с другим, можно взять приложение yed, или если не нарушаем nda, то взять ИИ, и коллег).
6.Писать ТЗ за основу беря, то что уже реализовано. Тут подключать менеджеров для того, чтобы презентовать заказчику вижен по автоматизации.
7.Когда мы поймём разницу и то, что нужно доработать, пойти к тим лидам и архитекторам и с ними проговорить. Обозначить будет ли этот набор фич риском или нет. Если да, то в оценку включать риски.
Нет смысла уходить в детали, для таких задач лучше выходить на уровень пользовательско-функциональных требований (тут мне хорошо оперировать use cases), и брать системный контекст, для понимания возможных интеграций.
Насчёт того, задача эта для какого уровня аналитика, я бы брала сеньора ну или крутого миддл. И соглашусь, что тут большой кусок менеджмента, чтобы продакт, руководитель проекта, заказчик выровняли своё понимание. Но с другой стороны крутить концепты и прыгать по абстракциям на разных уровнях, это сеньор конечно. Если есть архитектор, то тоже его задача и тим лида разработки.
🎯Главная цель - не написать в ТЗ, то, что будет "замедленной бомбой", а писать то, что 100% есть, а с другой стороны нужно заказчику и мы это 100% понимаем, если не понимаем, то лучше не писать)
Ну и конечно в идеале получить доступ к заказчику, с ним обсудить, на каком основании был составлен его документ и как его рассматривать, раз в нём откровенная чепуха.
Сильно бы на подобные документы я не опиралась и обозначала их как риски, потому что сложно из них что-то адекватное брать и двигаться дальше.
Но! Нужно понимать, что для нас любая документация от заказчика это исходник!
Я тут резво на него забила, но это вопросики...
Вот тут это тоже уровень сеньора, уметь сказать "нет", и аргументировать. Потому что сложный момент, который требует переговоров с заказчиком для корректировки его понимания. И аналитик, как детектив, примерно пытается понять, первопричину запроса заказчика. Это просто "хотелки" руководства, которые неправильно поняли, или же что-то под этим есть более глубокое?
Есть ещё такая, я бы сказала #ошибка_джуна или #смертельные_грехи_аналитика, когда не понимая процессы As Is, сразу пробуют зафиксировать To Be. И вот документ выходит некой чепухой, хоть и могут топить за то, что он To Be.
Спасибо за активность, непростая задача, и я вижу, что потребовалось время осознать, что я вообще тут намоделировала 😂
Пишу по пунктам алгоритм анализа, начиная с бизнес уровня:
1. Выяснить политический контекст ситуации. О чем договорились уже. Кто за что отвечает и какие есть, и есть ли, рычаги влияния. Тут по-хорошему карту заинтересованных лиц описать. И некий приоритет, кто в первом приоритете влияния.
2.Понять, что есть на нашей территории, и что мы делаем в рамках проекта. Иногда реально сложно понять, мы работаем над проектом или продуктом. Часто руководители говорят о продукте, но фактически его нет и идёт работа по проекту. У меня есть статья про разницу проекта и продукта, можно вот тут почитать.
3.Раз уже есть продукт или подобие продукта, а документы от заказчика противоречивые, то стоит изучить существующий вариант, по нему зафиксировать некий концепт. Проще всего предложить заказчику, то что уже есть.
4.Поговорить с коллегами, кто уже общался с заказчиком. По этим договорённостям составить тоже некий концепт. Я люблю графы, поэтому составляю mind maps по проектам.
5.Понять насколько то, что хочет заказчик или якобы хочет, отличается от текущей версии реализации (совместить один граф с другим, можно взять приложение yed, или если не нарушаем nda, то взять ИИ, и коллег).
6.Писать ТЗ за основу беря, то что уже реализовано. Тут подключать менеджеров для того, чтобы презентовать заказчику вижен по автоматизации.
7.Когда мы поймём разницу и то, что нужно доработать, пойти к тим лидам и архитекторам и с ними проговорить. Обозначить будет ли этот набор фич риском или нет. Если да, то в оценку включать риски.
Нет смысла уходить в детали, для таких задач лучше выходить на уровень пользовательско-функциональных требований (тут мне хорошо оперировать use cases), и брать системный контекст, для понимания возможных интеграций.
Насчёт того, задача эта для какого уровня аналитика, я бы брала сеньора ну или крутого миддл. И соглашусь, что тут большой кусок менеджмента, чтобы продакт, руководитель проекта, заказчик выровняли своё понимание. Но с другой стороны крутить концепты и прыгать по абстракциям на разных уровнях, это сеньор конечно. Если есть архитектор, то тоже его задача и тим лида разработки.
🎯Главная цель - не написать в ТЗ, то, что будет "замедленной бомбой", а писать то, что 100% есть, а с другой стороны нужно заказчику и мы это 100% понимаем, если не понимаем, то лучше не писать)
Ну и конечно в идеале получить доступ к заказчику, с ним обсудить, на каком основании был составлен его документ и как его рассматривать, раз в нём откровенная чепуха.
Сильно бы на подобные документы я не опиралась и обозначала их как риски, потому что сложно из них что-то адекватное брать и двигаться дальше.
Но! Нужно понимать, что для нас любая документация от заказчика это исходник!
Я тут резво на него забила, но это вопросики...
Вот тут это тоже уровень сеньора, уметь сказать "нет", и аргументировать. Потому что сложный момент, который требует переговоров с заказчиком для корректировки его понимания. И аналитик, как детектив, примерно пытается понять, первопричину запроса заказчика. Это просто "хотелки" руководства, которые неправильно поняли, или же что-то под этим есть более глубокое?
Есть ещё такая, я бы сказала #ошибка_джуна или #смертельные_грехи_аналитика, когда не понимая процессы As Is, сразу пробуют зафиксировать To Be. И вот документ выходит некой чепухой, хоть и могут топить за то, что он To Be.
❤
1
👍
1
🤩
1
Пост от 10.07.2026 13:00
93
0
0
Моделирую рабочую ситуацию!
Всех с летней пятницей, и для закрытия рабочей недели предлагаю подумать над кейсом. Рубрика #кейссолвинг
Я описываю ситуацию, вы предлагаете варианты выхода, задаёте вопросы, я на следующий день или позже пишу свой ответ)
Предыдущий кейс 🚀
Итак, вы системный аналитик на проекте, только пришли.
Проект уже как-то существует без вас, есть заказчик, есть коллеги (например, 3 человека и человек 10 разработки), они больше в теме договорённостей, и кто чего говорил заказчику и почему. Уже были какие-то встречи с заказчиком. И вот аналитику дают пакет документов от заказчика. Аналитик эти документы рассматривает, как исходный документ для выявления требований. Что вцелом логично. Но по факту оказывается, что это некая версия вижена от заказчика, как он хочет решать свои задачи. И конечно документ противоречит всему, что уже есть в команде, что разработано и зафиксировано в предыдущих итерациях общения.
У аналитика типичное поведение - "с этим работать невозможно", у руководителя проекта типичное поведение "ТЗ до завтра сделаешь?" и прекрасная речь, которая заканчивается вопросом "да, ведь?"
Исходно: аналитику доступно общение с коллегами, кто на проекте, восновном это руководство проектом и продуктом, который есть, есть описание продукта, его в том числе предлагают заказчику.
Продукт реализован в рамках другого проекта, для другого заказчика.
Доступа к новому заказчику нет, как вы уже поняли цель аналитика - написать ТЗ, для согласования с заказчиком.
❓Что посоветуете аналитику?
Какой видите план действий?
Я тут не написала уровень квалификации аналитика, даже интересно, что вы скажите какого уровня нужен аналитик на проекте? 😁
#кейссолвинг #выаналитик
---
😎О системном и бизнес анализе. Подписывайтесь и рекомендуйте друзьям, коллегам
😄СУП в вк
Всех с летней пятницей, и для закрытия рабочей недели предлагаю подумать над кейсом. Рубрика #кейссолвинг
Я описываю ситуацию, вы предлагаете варианты выхода, задаёте вопросы, я на следующий день или позже пишу свой ответ)
Предыдущий кейс 🚀
Итак, вы системный аналитик на проекте, только пришли.
Проект уже как-то существует без вас, есть заказчик, есть коллеги (например, 3 человека и человек 10 разработки), они больше в теме договорённостей, и кто чего говорил заказчику и почему. Уже были какие-то встречи с заказчиком. И вот аналитику дают пакет документов от заказчика. Аналитик эти документы рассматривает, как исходный документ для выявления требований. Что вцелом логично. Но по факту оказывается, что это некая версия вижена от заказчика, как он хочет решать свои задачи. И конечно документ противоречит всему, что уже есть в команде, что разработано и зафиксировано в предыдущих итерациях общения.
У аналитика типичное поведение - "с этим работать невозможно", у руководителя проекта типичное поведение "ТЗ до завтра сделаешь?" и прекрасная речь, которая заканчивается вопросом "да, ведь?"
Исходно: аналитику доступно общение с коллегами, кто на проекте, восновном это руководство проектом и продуктом, который есть, есть описание продукта, его в том числе предлагают заказчику.
Продукт реализован в рамках другого проекта, для другого заказчика.
Доступа к новому заказчику нет, как вы уже поняли цель аналитика - написать ТЗ, для согласования с заказчиком.
❓Что посоветуете аналитику?
Какой видите план действий?
Я тут не написала уровень квалификации аналитика, даже интересно, что вы скажите какого уровня нужен аналитик на проекте? 😁
#кейссолвинг #выаналитик
---
😎О системном и бизнес анализе. Подписывайтесь и рекомендуйте друзьям, коллегам
😄СУП в вк
❤
1