Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «Риски Частного Капитала»

Подписчики
Всего
1 338
Сегодня
0
Просмотров на пост
Всего
323
ER
Общий
24.14%
Суточный
21.4%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 3 из 334 постов
Смотреть все посты
Пост от 26.07.2026 22:10
149
0
7
Обсуждают, как мексиканский бизнесмен Рикардо Салинас (Ricardo Salinas Pliego), чуть не потерял иск на 💵315+ млн из-за Black Cube (Salinas Pliego & Anor v Astor Asset Management 3 Ltd & Ors [2026] EWCA Civ 940; решение от 21 July 2026).
Когда в 2021 г-ну Салинасу понадобилось занять крупную сумму, ему порекомендовали Astor Capital Fund, якобы, управлявший деньгами семейства Асторов, восходящих к магнату Джону Джейкобу Астору, и свели с некими Грегори Митчелом и Томасом Мелоном. Они одолжили ему 💵115 млн [в песо] пятью траншами под залог его пакета акций Grupo Elektra SAB de CV стоимостью 💵415 млн. Залог передали на хранение компаниями с Багамов и Монако.
Выяснилось, что «Митчел» — это Вел Скляров, а Мелон - его помощник Алексей Скачков. Пользуясь “туманными” условиями договора, Скляров перевел заложенные бумаги на себя и продал, отдав часть средств взаймы г-ну Салинасу, т. е. владельцу бумаг, а разницу 💵217 млн оставил себе (§15 решения апелляции). Потом объявил заёмщику дефолт за невыплату % и расходов.
В августе 2024 г-н Салинас и его компания предъявили иск в Высокий Суд к Склярову и его "фондам", получив WFO (оставлен в силе 7.10.24; [2024] EWHC 2522 (Comm)).
Ответчик настаивал, что договор допускал “rehypothecation” акций - распоряжение залогом, иначе займ не был бы по такой низкой ставке, а имя «Астор» использует для бизнеса (говорит, в мире тысячи таких компаний); назвался Митчелом, потому что «Владимир» непопулярно в США, и чтобы не опасаться дискриминации из-за еврейского происхождения и украинского гражданства (§18-19).
Видимо мексиканцам показалось, что английским иском и мерами не обойтись. Для сбора разведданных наняли Black Cube, которые специализируются на операциях “под прикрытием”; их сотрудник, придумав легенду, встречается с лицом, у которого нужно получить информацию, и последнее делится ею, не понимая, кто перед ним, пока его скрытно записывают.
Решили разговорить солиситоров ответчика - DWF Law (§31). Детектив представился им как Марко Ортелли от итальянской нефтяной компании, которая собирается подавать в арбитраж на правительство ОАЭ из-за совместного бизнеса. После сессии по Zoom встретились в Амстердаме в ноябре 2024, где на 5.5-часовом ужине с вином “м-р Ортелли" спрашивал солиситора прj стратегию защиты, последствия обеспечительных мер и перспективы урегулирования. Аудио/видео передали истцу (§3).
В феврале 2025 “Ортелли” свернул общение с DWF, а 5.3.25 истец подал в суд заявление, на основании собранной информации о вынесении summary judgment по вопросу ответственности Склярова за ущерб, либо о переводе на его счёт обеспечения 💵315 млн.
Ответчик поменял солиситоров (общавшийся с Black Cube попал под дисциплинарку) и в июне 2025 попросил прекратить дело из-за abuse of process со стороны истца.
Истцу тоже пришлось сменить команду, т. к. Enyo Law отказались смотреть материалы от Black Cube.
Суд первой инстанции 13.11.25, признав, что истец злоупотребил, ограничился strike out ходатайства о summary judgment ([2025] EWHC 2968 (Comm)). Охота за информацией солиситоров названа “анафемой для норм и ценностей гражданского процесса” (§61).
Апелляция, согласившись, что прекращение рассмотрения всего иска — это неадекватная мера, в качестве дополнительной санкции отменила WFO, поскольку найм детективов шёл одновременно c подачей на меры и был скрыт от Суда.
Следующее заседание по иску к Склярову в ноябре 2026, а в мае 2026 ФБР арестовало его в Чикаго, после чего ему предъявили обвинения в мошенничестве на 💵450 млн (из обвинения выяснилось, что он также известен как Марк Саймон Бентли).
В 2025 г-н Салинас сказал WSJ: “Чувствую, как абсолютный идиот. Как я мог попасться?»
Ранее рассказывал, как Black Cube попытались собрать “компромат” на бывшего судью Фрэнка Ньюболда (в деле Склярова Суд вспомнил эту историю), а также, как они помогли дочери бывшего президента Анголы собрать доказательства для иска в Лондоне.
Когда в 2021 г-ну Салинасу понадобилось занять крупную сумму, ему порекомендовали Astor Capital Fund, якобы, управлявший деньгами семейства Асторов, восходящих к магнату Джону Джейкобу Астору, и свели с некими Грегори Митчелом и Томасом Мелоном. Они одолжили ему 💵115 млн [в песо] пятью траншами под залог его пакета акций Grupo Elektra SAB de CV стоимостью 💵415 млн. Залог передали на хранение компаниями с Багамов и Монако.
Выяснилось, что «Митчел» — это Вел Скляров, а Мелон - его помощник Алексей Скачков. Пользуясь “туманными” условиями договора, Скляров перевел заложенные бумаги на себя и продал, отдав часть средств взаймы г-ну Салинасу, т. е. владельцу бумаг, а разницу 💵217 млн оставил себе (§15 решения апелляции). Потом объявил заёмщику дефолт за невыплату % и расходов.
В августе 2024 г-н Салинас и его компания предъявили иск в Высокий Суд к Склярову и его "фондам", получив WFO (оставлен в силе 7.10.24; [2024] EWHC 2522 (Comm)).
Ответчик настаивал, что договор допускал “rehypothecation” акций - распоряжение залогом, иначе займ не был бы по такой низкой ставке, а имя «Астор» использует для бизнеса (говорит, в мире тысячи таких компаний); назвался Митчелом, потому что «Владимир» непопулярно в США, и чтобы не опасаться дискриминации из-за еврейского происхождения и украинского гражданства (§18-19).
Видимо мексиканцам показалось, что английским иском и мерами не обойтись. Для сбора разведданных наняли Black Cube, которые специализируются на операциях “под прикрытием”; их сотрудник, придумав легенду, встречается с лицом, у которого нужно получить информацию, и последнее делится ею, не понимая, кто перед ним, пока его скрытно записывают.
Решили разговорить солиситоров ответчика - DWF Law (§31). Детектив представился им как Марко Ортелли от итальянской нефтяной компании, которая собирается подавать в арбитраж на правительство ОАЭ из-за совместного бизнеса. После сессии по Zoom встретились в Амстердаме в ноябре 2024, где на 5.5-часовом ужине с вином “м-р Ортелли" спрашивал солиситора прj стратегию защиты, последствия обеспечительных мер и перспективы урегулирования. Аудио/видео передали истцу (§3).
В феврале 2025 “Ортелли” свернул общение с DWF, а 5.3.25 истец подал в суд заявление, на основании собранной информации о вынесении summary judgment по вопросу ответственности Склярова за ущерб, либо о переводе на его счёт обеспечения 💵315 млн.
Ответчик поменял солиситоров (общавшийся с Black Cube попал под дисциплинарку) и в июне 2025 попросил прекратить дело из-за abuse of process со стороны истца.
Истцу тоже пришлось сменить команду, т. к. Enyo Law отказались смотреть материалы от Black Cube.
Суд первой инстанции 13.11.25, признав, что истец злоупотребил, ограничился strike out ходатайства о summary judgment ([2025] EWHC 2968 (Comm)). Охота за информацией солиситоров названа “анафемой для норм и ценностей гражданского процесса” (§61).
Апелляция, согласившись, что прекращение рассмотрения всего иска — это неадекватная мера, в качестве дополнительной санкции отменила WFO, поскольку найм детективов шёл одновременно c подачей на меры и был скрыт от Суда.
Следующее заседание по иску к Склярову в ноябре 2026, а в мае 2026 ФБР арестовало его в Чикаго, после чего ему предъявили обвинения в мошенничестве на 💵450 млн (из обвинения выяснилось, что он также известен как Марк Саймон Бентли).
В 2025 г-н Салинас сказал WSJ: “Чувствую, как абсолютный идиот. Как я мог попасться?»
Ранее рассказывал, как Black Cube попытались собрать “компромат” на бывшего судью Фрэнка Ньюболда (в деле Склярова Суд вспомнил эту историю), а также, как они помогли дочери бывшего президента Анголы собрать доказательства для иска в Лондоне.

Пост от 19.07.2026 16:35
116
0
4
Сбор налогов с состоятельных остаётся в приоритете.
Во Франции апелляция на 2-м круге отменила решение 2020-го, восстановив недоимку 💶22.5 млн Бернару Арно и его супруге.
Дело тянется более 6 лет и связано со схемой владения бизнесом через бельгийский холдинг. C 1994 по 2003 г-н Арно получил опционов на акции своих французских компаний на 💶131.17 млн, которые затем превратились в акции добав. стоимостью 💶249.8 млн. Взимание налога с этой суммы было отложено до продажи акций. В 2005–07 акции внесли в уставный капитал бельгийской компании г-на Арно (99%-1 акция) по цене 💶368.5 млн. Налогов после этой сделки также не было. В апреле 2010 бельгийская компания уменьшила уставный капитал через уменьшение номинальной стоимости акций, выплатив г-ну Арно как учредителю 💶49,97 млн. Французская налоговая посчитала выплату доходом, т.к. уменьшение капитала не связано с убытками, доначислив 💶30.2 млн подоходного, соц. выплат, а также “налога на богатство” за 2012-15 (Impôt de solidarité sur la fortune; придуман социалистами и действовал во Франции до 2017 на доходы св. 💶1.3 млн).
Админ. суд Парижа (1-я инстанция) встал на сторону бизнесмена, аннулировав решение налоговой 2.12.20. Решение устояло в апелляции (15.12.23), но кассация (1.7.25) направила жалобу правительства на новое рассмотрение в апелляцию, которая вернула недоимку, чуть снизив (22.5 млн). Представитель г-на Арно сказал, будут обжаловать.
FT пишут, что в ответ на идею Президента Оланда о 75% налоге на доходы св. 💶1 млн г-н Арно подавал на бельгийское гражданство (2012), но передумал.
Ранее Француженка Лилиан Бетанкур (Liliane Bettencourt) была вынуждена продать свой “секретный” остров Д’Арро в Сейшельском архипелаге в 2012 после того, как налоговая обнаружила его и оффшорные счета. Погасив недоимку и пени 💶103 млн, владелица доли в L’Oréal избежала уголовного дела.
Калифорнийские IT и “крипто” миллиардеры вкладывают 💵млн в блокировку законопроекта о 5% налоге на богатство, референдум по которому должен пройти в штате в ноябре 2026 (согл. FT Сергей Брин потратил 💵82 млн). Предполагается, что налог, цель которого заместить 💵100 млрд субсидий на здравоохранение, изъятых федеральным правительством, возьмут “задним числом” с 1.1.26. Поэтому многие в 2025 поспешили купить дома в соседнем штате на оз.Тахо (шато от 💵3-4 млн), чтобы указать местом жительства в декларации 2026-го. Но статус резидента не так легко прекратить. Налоговики Калифорнии будут проверять, куда дети ходят в школу, где зарегистрированы машины, где лечится семья и её 4-ногие, и т.д. Эта позиция перекликается с британской «методичкой», требующей проверять членство в закрытых клубах (придумывают 90-дневное членство для non-doms).
Тем временем адвокатам Дональда Трампа не удалось “засилить” мировое соглашение по начатому ими спору с федеральной налоговой (IRS) из-за “слива” информации о президенте и его семье. Согласно мировому 18.5.26, не представлявшемуся для утверждения суду, государство обязывалось навсегда освободить г-на Трампа и его сыновей от каких-либо налоговых претензий. Далее в суд было подано ходатайство о прекращении дела, удовлетворённое судьёй Кэтлин Вильямс (Kathleen Williams; назн. Президентом Обамой 2011). Узнав об этом, 35 судей в отставке 27.5.26 подали ход-во с amicus brief, попросив возобновить процесс, поскольку иск и мировое — это “мошенничество над судом” (fraud on the Court). Суд возобновил, запросив дополнительные пояснения и 13.7.26 пересмотрел итог, посчитав, что (а) никакого спора изначально не было (совпадение истца и ответчика, т.к. Президент контролирует казначейство и прокуратуру), и (б) целью иска была “попытка использовать суд, чтобы придать легитимность соглашению о предоставлении иммунитета людям и компаниям, аффилированным с Президентом и забрать 💵млрд у американских налогоплательщиков за претензии, не предусмотренные законом” (с 55-56 решения 13.7.26).
Ранее рассказывал, как г-н Арно разнёс идею 2% налога на богатых, и как он м.б. связан с историей Пьеша.
Во Франции апелляция на 2-м круге отменила решение 2020-го, восстановив недоимку 💶22.5 млн Бернару Арно и его супруге.
Дело тянется более 6 лет и связано со схемой владения бизнесом через бельгийский холдинг. C 1994 по 2003 г-н Арно получил опционов на акции своих французских компаний на 💶131.17 млн, которые затем превратились в акции добав. стоимостью 💶249.8 млн. Взимание налога с этой суммы было отложено до продажи акций. В 2005–07 акции внесли в уставный капитал бельгийской компании г-на Арно (99%-1 акция) по цене 💶368.5 млн. Налогов после этой сделки также не было. В апреле 2010 бельгийская компания уменьшила уставный капитал через уменьшение номинальной стоимости акций, выплатив г-ну Арно как учредителю 💶49,97 млн. Французская налоговая посчитала выплату доходом, т.к. уменьшение капитала не связано с убытками, доначислив 💶30.2 млн подоходного, соц. выплат, а также “налога на богатство” за 2012-15 (Impôt de solidarité sur la fortune; придуман социалистами и действовал во Франции до 2017 на доходы св. 💶1.3 млн).
Админ. суд Парижа (1-я инстанция) встал на сторону бизнесмена, аннулировав решение налоговой 2.12.20. Решение устояло в апелляции (15.12.23), но кассация (1.7.25) направила жалобу правительства на новое рассмотрение в апелляцию, которая вернула недоимку, чуть снизив (22.5 млн). Представитель г-на Арно сказал, будут обжаловать.
FT пишут, что в ответ на идею Президента Оланда о 75% налоге на доходы св. 💶1 млн г-н Арно подавал на бельгийское гражданство (2012), но передумал.
Ранее Француженка Лилиан Бетанкур (Liliane Bettencourt) была вынуждена продать свой “секретный” остров Д’Арро в Сейшельском архипелаге в 2012 после того, как налоговая обнаружила его и оффшорные счета. Погасив недоимку и пени 💶103 млн, владелица доли в L’Oréal избежала уголовного дела.
Калифорнийские IT и “крипто” миллиардеры вкладывают 💵млн в блокировку законопроекта о 5% налоге на богатство, референдум по которому должен пройти в штате в ноябре 2026 (согл. FT Сергей Брин потратил 💵82 млн). Предполагается, что налог, цель которого заместить 💵100 млрд субсидий на здравоохранение, изъятых федеральным правительством, возьмут “задним числом” с 1.1.26. Поэтому многие в 2025 поспешили купить дома в соседнем штате на оз.Тахо (шато от 💵3-4 млн), чтобы указать местом жительства в декларации 2026-го. Но статус резидента не так легко прекратить. Налоговики Калифорнии будут проверять, куда дети ходят в школу, где зарегистрированы машины, где лечится семья и её 4-ногие, и т.д. Эта позиция перекликается с британской «методичкой», требующей проверять членство в закрытых клубах (придумывают 90-дневное членство для non-doms).
Тем временем адвокатам Дональда Трампа не удалось “засилить” мировое соглашение по начатому ими спору с федеральной налоговой (IRS) из-за “слива” информации о президенте и его семье. Согласно мировому 18.5.26, не представлявшемуся для утверждения суду, государство обязывалось навсегда освободить г-на Трампа и его сыновей от каких-либо налоговых претензий. Далее в суд было подано ходатайство о прекращении дела, удовлетворённое судьёй Кэтлин Вильямс (Kathleen Williams; назн. Президентом Обамой 2011). Узнав об этом, 35 судей в отставке 27.5.26 подали ход-во с amicus brief, попросив возобновить процесс, поскольку иск и мировое — это “мошенничество над судом” (fraud on the Court). Суд возобновил, запросив дополнительные пояснения и 13.7.26 пересмотрел итог, посчитав, что (а) никакого спора изначально не было (совпадение истца и ответчика, т.к. Президент контролирует казначейство и прокуратуру), и (б) целью иска была “попытка использовать суд, чтобы придать легитимность соглашению о предоставлении иммунитета людям и компаниям, аффилированным с Президентом и забрать 💵млрд у американских налогоплательщиков за претензии, не предусмотренные законом” (с 55-56 решения 13.7.26).
Ранее рассказывал, как г-н Арно разнёс идею 2% налога на богатых, и как он м.б. связан с историей Пьеша.
Пост от 05.07.2026 13:36
1
0
0
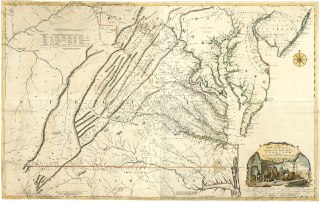
Разглядывая картуш на карте Вирджинии и Мэриленда Фрея-Джефферсона, FT пытались понять, как зарабатывали и сохраняли американские колонисты XVIII в.
К середине XVIII на окраинах колонии стали появляться французы, и британцам, чтобы отстаивать права, была остро нужна карта новых земель. По запросу метрополии губернатор Льюис Бёрвэл нанял картографов Джошуа Фрая и Питера Джефферсона, отца 3-го Президента США. Они справились за год, сдав работу в 1751. Британский Минторг выплатил каждому по 💷150. Карта стала собственностью Короны, издавалась тысячи раз и помогла установить границы США после Войны за независимость (1783).
На картуше в правом нижнем углу пристань виргинской реки. Трое чернокожих рабов под надзором управляющего грузят бочки с высушенными листьями табака на торговый парусник. Ещё один раб подносит бокал красного белому плантатору, который сидит, опираясь на трость, выслушивая другого белого.
Табак, поставляемый в Англию, Шотландию и Голландию, приносил основной доход (достаток к сер. XVIII превышал средне-британский), но была проблема в трудовых ресурсах для его выращивания. В XVII использовали, в основном, труд приезжих англичан, продававшихся в кабалу за еду и проезд через Атлантику (indentured), отпускаемых на свободу через 4-7 лет на плантациях (80% рабсилы в 1670-х, по данным Музея истории и культуры Вирджинии). Первый “груз” африканских рабов прибыл в 1619 (украден английскими privateers у португальцев), а к началу XVII, когда к работорговле подключились британцы, рабы составляли большинство workforce и обязательную часть активов землевладельцев. По закону 1662 (часть т.н. “Чёрного Кодекса”) дети рабынь автоматически становились рабами, и права рабовладельцев стали наследуемыми (в Англии рабство признает незаконным в 1772 Лорд Мэнсфилд решением Sommersett v Steuart).
Колониям запрещалось печатать деньги, поэтому для расчётов пользовались испанскими серебряным долларами (пиастры; легко делились на 8 частей), а также брит. фунтом. Монет не хватало; использовались суррогаты, например, “кредитные обязательства” (bills of credit) местных ассамблей, обеспечиваемые портовыми или земельными сборами.
Историк Элис Хансон Джонс (Alice Hanson Jones), исследовавшая списки наследственных масс (probate records) с 1774, установила, что деньги составляли где-то 5%. Основная часть - обязательства, отражаемые в балансах требований (ledgers). Торговцы, владельцы баров или магазинов отпускали товар землякам в кредит, регулярно погашаемый деньгами или товарами (табак, пушнина и пр.), либо векселями. При открытии наследства в газете выходило объявление с призывом рассчитаться с наследственной массой такого-то.
Земли и дом были источником богатства, местом для проживания и “пенсионным” активом (рента). Фермы передавались через поколения. Учёт прав вёлся на местах и оборот земли был легче, чем в Англии. Кредиторы могли получить землю, отданную в обеспечение, в случае дефолта (долговые тюрьмы были ещё в XIX). Джентльмены отличались от «простых» возможностью давать и брать взаймы. Жена теряла эту возможность, уйдя от мужа, о чём объявлялось в газете.
Пенсионной системы не было. Единицы могли позволить уйти на покой. Обычно работали, пока могли физически (доживали до 60-70 лет). Системы страхования не было и, в случае несчастья, полагались на помощь семьи, соседей или церкви.
Банков не было; сохранять во вкладах начали уже после независимости в XIX в (те, кто вёл торговлю через Атлантику, даже несмотря на войны были богаче за счёт свободного доступа к валюте).
После обретения независимости США начали выпуск собственных банкнот (1791), и придумали гособлигации (Treasurys), что понизило важность земли как средства сбережения.
Ранее рассказывал, как пристрастие Томаса Джефферсона к фр. кухне и приёмам поставило отца-основателя на грань разорения на 82-м году; краудфандинг не помог, и вирджинское поместье Монтичелло было продано с торгов вместе с несколькими сотнями рабов в 1827.
К середине XVIII на окраинах колонии стали появляться французы, и британцам, чтобы отстаивать права, была остро нужна карта новых земель. По запросу метрополии губернатор Льюис Бёрвэл нанял картографов Джошуа Фрая и Питера Джефферсона, отца 3-го Президента США. Они справились за год, сдав работу в 1751. Британский Минторг выплатил каждому по 💷150. Карта стала собственностью Короны, издавалась тысячи раз и помогла установить границы США после Войны за независимость (1783).
На картуше в правом нижнем углу пристань виргинской реки. Трое чернокожих рабов под надзором управляющего грузят бочки с высушенными листьями табака на торговый парусник. Ещё один раб подносит бокал красного белому плантатору, который сидит, опираясь на трость, выслушивая другого белого.
Табак, поставляемый в Англию, Шотландию и Голландию, приносил основной доход (достаток к сер. XVIII превышал средне-британский), но была проблема в трудовых ресурсах для его выращивания. В XVII использовали, в основном, труд приезжих англичан, продававшихся в кабалу за еду и проезд через Атлантику (indentured), отпускаемых на свободу через 4-7 лет на плантациях (80% рабсилы в 1670-х, по данным Музея истории и культуры Вирджинии). Первый “груз” африканских рабов прибыл в 1619 (украден английскими privateers у португальцев), а к началу XVII, когда к работорговле подключились британцы, рабы составляли большинство workforce и обязательную часть активов землевладельцев. По закону 1662 (часть т.н. “Чёрного Кодекса”) дети рабынь автоматически становились рабами, и права рабовладельцев стали наследуемыми (в Англии рабство признает незаконным в 1772 Лорд Мэнсфилд решением Sommersett v Steuart).
Колониям запрещалось печатать деньги, поэтому для расчётов пользовались испанскими серебряным долларами (пиастры; легко делились на 8 частей), а также брит. фунтом. Монет не хватало; использовались суррогаты, например, “кредитные обязательства” (bills of credit) местных ассамблей, обеспечиваемые портовыми или земельными сборами.
Историк Элис Хансон Джонс (Alice Hanson Jones), исследовавшая списки наследственных масс (probate records) с 1774, установила, что деньги составляли где-то 5%. Основная часть - обязательства, отражаемые в балансах требований (ledgers). Торговцы, владельцы баров или магазинов отпускали товар землякам в кредит, регулярно погашаемый деньгами или товарами (табак, пушнина и пр.), либо векселями. При открытии наследства в газете выходило объявление с призывом рассчитаться с наследственной массой такого-то.
Земли и дом были источником богатства, местом для проживания и “пенсионным” активом (рента). Фермы передавались через поколения. Учёт прав вёлся на местах и оборот земли был легче, чем в Англии. Кредиторы могли получить землю, отданную в обеспечение, в случае дефолта (долговые тюрьмы были ещё в XIX). Джентльмены отличались от «простых» возможностью давать и брать взаймы. Жена теряла эту возможность, уйдя от мужа, о чём объявлялось в газете.
Пенсионной системы не было. Единицы могли позволить уйти на покой. Обычно работали, пока могли физически (доживали до 60-70 лет). Системы страхования не было и, в случае несчастья, полагались на помощь семьи, соседей или церкви.
Банков не было; сохранять во вкладах начали уже после независимости в XIX в (те, кто вёл торговлю через Атлантику, даже несмотря на войны были богаче за счёт свободного доступа к валюте).
После обретения независимости США начали выпуск собственных банкнот (1791), и придумали гособлигации (Treasurys), что понизило важность земли как средства сбережения.
Ранее рассказывал, как пристрастие Томаса Джефферсона к фр. кухне и приёмам поставило отца-основателя на грань разорения на 82-м году; краудфандинг не помог, и вирджинское поместье Монтичелло было продано с торгов вместе с несколькими сотнями рабов в 1827.