Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «Постоянный репозиторий по Python»

Подписчики
Всего
1 833
Сегодня
0
Просмотров на пост
Всего
144
ER
Общий
7.77%
Суточный
5.6%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 363 постов
Смотреть все посты
Пост от 29.07.2026 10:55
1
0
0
Пост от 29.07.2026 10:55
1
0
0

Пост от 20.07.2026 10:47
34
0
1
🐍 sorted()не изменяет список. И это спасает от многих ошибок.
Представьте ситуацию.
Есть список:
numbers = [5, 1, 8, 3, 2]
Вы хотите вывести его в отсортированном виде и пишете:
print(sorted(numbers))
Получаете: [1, 2, 3, 5, 8]
А теперь проверим исходный список:
print(numbers)
Результат: [5, 1, 8, 3, 2]
Он не изменился.
Многие думают, что это ошибка
Но именно так и задумано.
Функция sorted() создаёт новый отсортированный список, не изменяя исходные данные.
Это очень удобно, когда:
данные нужны ещё и в первоначальном порядке;
один и тот же список используется в разных частях программы;
нужно избежать случайного изменения данных.
А вот sort() работает иначе
numbers.sort()
После этого:
print(numbers)
получим: [1, 2, 3, 5, 8]
Теперь список изменился навсегда.
Что выбрать?
Используйте sorted(), если:
✅ нужно сохранить исходные данные;
✅ хотите получить новую отсортированную коллекцию;
✅ работаете в функциональном стиле.
Используйте sort(), если:
✅ список больше нигде не нужен в исходном виде;
✅ важна экономия памяти;
✅ сортировка выполняется «на месте».
Интересный факт
sorted() работает не только со списками.
Она умеет сортировать практически любые итерируемые объекты:
sorted("python")
['h', 'n', 'o', 'p', 't', 'y']
или даже:
sorted({5, 2, 9, 1})
[1, 2, 5, 9]
о есть результатом sorted() всегда будет список, независимо от типа исходной коллекции.
💡 Запомнить просто
sorted() — создаёт новый список.
sort() — изменяет существующий.
Это небольшое различие помогает избежать множества трудноуловимых ошибок, особенно в больших проектах.
Представьте ситуацию.
Есть список:
numbers = [5, 1, 8, 3, 2]
Вы хотите вывести его в отсортированном виде и пишете:
print(sorted(numbers))
Получаете: [1, 2, 3, 5, 8]
А теперь проверим исходный список:
print(numbers)
Результат: [5, 1, 8, 3, 2]
Он не изменился.
Многие думают, что это ошибка
Но именно так и задумано.
Функция sorted() создаёт новый отсортированный список, не изменяя исходные данные.
Это очень удобно, когда:
данные нужны ещё и в первоначальном порядке;
один и тот же список используется в разных частях программы;
нужно избежать случайного изменения данных.
А вот sort() работает иначе
numbers.sort()
После этого:
print(numbers)
получим: [1, 2, 3, 5, 8]
Теперь список изменился навсегда.
Что выбрать?
Используйте sorted(), если:
✅ нужно сохранить исходные данные;
✅ хотите получить новую отсортированную коллекцию;
✅ работаете в функциональном стиле.
Используйте sort(), если:
✅ список больше нигде не нужен в исходном виде;
✅ важна экономия памяти;
✅ сортировка выполняется «на месте».
Интересный факт
sorted() работает не только со списками.
Она умеет сортировать практически любые итерируемые объекты:
sorted("python")
['h', 'n', 'o', 'p', 't', 'y']
или даже:
sorted({5, 2, 9, 1})
[1, 2, 5, 9]
о есть результатом sorted() всегда будет список, независимо от типа исходной коллекции.
💡 Запомнить просто
sorted() — создаёт новый список.
sort() — изменяет существующий.
Это небольшое различие помогает избежать множества трудноуловимых ошибок, особенно в больших проектах.
👍
3
❤
2
🔥
1
Пост от 13.07.2026 11:38
43
0
0
🐍 Миф: если код короче — значит он лучше
У Python есть репутация языка, на котором можно писать очень компактный код.
Но иногда желание написать всё в одну строку приводит к обратному эффекту.
Например:
result = [x**2 for x in numbers if x % 2 == 0 and x > 10 and x < 100]
Такой код вполне корректен.
Но попробуйте понять его через полгода.
А теперь сравните с этим вариантом:
result = []
for number in numbers:
if number % 2 != 0:
continue
if number <= 10 or number >= 100:
continue
result.append(number ** 2)
Да, строк больше. Но логика читается буквально сверху вниз.
Почему опытные разработчики не гонятся за минимальным количеством строк?
Потому что код гораздо чаще читают, чем пишут.
Причём читает его не только коллега.
Через несколько месяцев этим «коллегой» можете оказаться вы сами.
Что говорит философия Python?
В модуле this есть одна очень известная строка:
Beautiful is better than ugly.
И ещё одна, которая подходит к этой теме ещё лучше:
Readability counts.
«Читаемость имеет значение.»
Именно эта идея лежит в основе Python.
Когда короткий код — это хорошо?
✅ Простая операция.
✅ Очевидная логика.
✅ Конструкция легко читается.
Когда лучше написать подробнее?
Если приходится:
перечитывать выражение несколько раз;
добавлять комментарии, чтобы объяснить одну строку;
использовать слишком много вложенных условий.
В этих случаях лучше разбить решение на несколько шагов.
💡 Хороший ориентир
Задайте себе простой вопрос:
Сможет ли другой разработчик понять этот код за 10–15 секунд?
Если ответ «нет», возможно, стоит пожертвовать несколькими строками ради понятности.
Вывод
Хороший Python-код — это не тот, который помещается в одну строку.
Хороший Python-код — это тот, который легко читать, сопровождать и изменять.
Именно поэтому опытные разработчики часто выбирают простоту, а не краткость.
У Python есть репутация языка, на котором можно писать очень компактный код.
Но иногда желание написать всё в одну строку приводит к обратному эффекту.
Например:
result = [x**2 for x in numbers if x % 2 == 0 and x > 10 and x < 100]
Такой код вполне корректен.
Но попробуйте понять его через полгода.
А теперь сравните с этим вариантом:
result = []
for number in numbers:
if number % 2 != 0:
continue
if number <= 10 or number >= 100:
continue
result.append(number ** 2)
Да, строк больше. Но логика читается буквально сверху вниз.
Почему опытные разработчики не гонятся за минимальным количеством строк?
Потому что код гораздо чаще читают, чем пишут.
Причём читает его не только коллега.
Через несколько месяцев этим «коллегой» можете оказаться вы сами.
Что говорит философия Python?
В модуле this есть одна очень известная строка:
Beautiful is better than ugly.
И ещё одна, которая подходит к этой теме ещё лучше:
Readability counts.
«Читаемость имеет значение.»
Именно эта идея лежит в основе Python.
Когда короткий код — это хорошо?
✅ Простая операция.
✅ Очевидная логика.
✅ Конструкция легко читается.
Когда лучше написать подробнее?
Если приходится:
перечитывать выражение несколько раз;
добавлять комментарии, чтобы объяснить одну строку;
использовать слишком много вложенных условий.
В этих случаях лучше разбить решение на несколько шагов.
💡 Хороший ориентир
Задайте себе простой вопрос:
Сможет ли другой разработчик понять этот код за 10–15 секунд?
Если ответ «нет», возможно, стоит пожертвовать несколькими строками ради понятности.
Вывод
Хороший Python-код — это не тот, который помещается в одну строку.
Хороший Python-код — это тот, который легко читать, сопровождать и изменять.
Именно поэтому опытные разработчики часто выбирают простоту, а не краткость.
👍
2
❤
1
🔥
1
Пост от 10.07.2026 10:38
15
0
0
👏
1
Пост от 10.07.2026 10:38
14
0
0
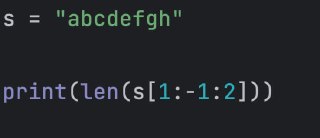
Пост от 07.07.2026 10:12
14
0
0
🐍 for ... else — одна из самых необычных конструкций Python
Если спросить опытных разработчиков, какую конструкцию Python они используют реже всего, многие назовут именно for ... else.
Хотя на самом деле она может сделать код намного понятнее.
Посмотрите на пример.
numbers = [4, 8, 15, 16, 23, 42]
for number in numbers:
if number == 15:
print("Число найдено")
break
else:
print("Число отсутствует")
На первый взгляд кажется, что else относится к if.
Но это не так.
Как работает else у цикла?
Блок else выполнится только в том случае, если цикл завершился естественным образом.
Если во время работы встретился break, то else пропускается.
То есть логика выглядит так:
Цикл завершился без break?
│
Да ─────────► Выполнить else
│
Нет ────────► Пропустить else
Где это действительно удобно?
Например, при поиске элемента.
Без for...else обычно пишут так:
found = False
for number in numbers:
if number == 15:
found = True
break
if not found:
print("Число отсутствует")
Приходится заводить дополнительную переменную found, которая нужна только для контроля логики.
С for...else она больше не нужна.
Почему эту конструкцию редко используют?
Есть две причины:
- многие разработчики просто не знают о её существовании;
- некоторые считают её менее очевидной, чем обычный флаг.
Поэтому в разных командах отношение к for...else отличается.
Когда использовать?
✅ поиск элемента;
✅ проверка выполнения условия;
✅ ситуации, где нужен break.
А вот если внутри цикла нет break, то else практически теряет смысл.
💡 Интересный факт
Похожая конструкция есть и у цикла while.
То есть else может использоваться не только с if, но и с циклами — это одна из уникальных особенностей Python, которой нет в большинстве популярных языков программирования.
❓ А вы когда-нибудь использовали for...else?
👍 Да, регулярно.
🤔 Знал, но ни разу не применял.
😮 Сегодня узнал, что такое вообще существует.
Если спросить опытных разработчиков, какую конструкцию Python они используют реже всего, многие назовут именно for ... else.
Хотя на самом деле она может сделать код намного понятнее.
Посмотрите на пример.
numbers = [4, 8, 15, 16, 23, 42]
for number in numbers:
if number == 15:
print("Число найдено")
break
else:
print("Число отсутствует")
На первый взгляд кажется, что else относится к if.
Но это не так.
Как работает else у цикла?
Блок else выполнится только в том случае, если цикл завершился естественным образом.
Если во время работы встретился break, то else пропускается.
То есть логика выглядит так:
Цикл завершился без break?
│
Да ─────────► Выполнить else
│
Нет ────────► Пропустить else
Где это действительно удобно?
Например, при поиске элемента.
Без for...else обычно пишут так:
found = False
for number in numbers:
if number == 15:
found = True
break
if not found:
print("Число отсутствует")
Приходится заводить дополнительную переменную found, которая нужна только для контроля логики.
С for...else она больше не нужна.
Почему эту конструкцию редко используют?
Есть две причины:
- многие разработчики просто не знают о её существовании;
- некоторые считают её менее очевидной, чем обычный флаг.
Поэтому в разных командах отношение к for...else отличается.
Когда использовать?
✅ поиск элемента;
✅ проверка выполнения условия;
✅ ситуации, где нужен break.
А вот если внутри цикла нет break, то else практически теряет смысл.
💡 Интересный факт
Похожая конструкция есть и у цикла while.
То есть else может использоваться не только с if, но и с циклами — это одна из уникальных особенностей Python, которой нет в большинстве популярных языков программирования.
❓ А вы когда-нибудь использовали for...else?
👍 Да, регулярно.
🤔 Знал, но ни разу не применял.
😮 Сегодня узнал, что такое вообще существует.
😨
1