Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «AI для Всех»

AI для Всех
1.4K
5.2K
882
636
21.7K
Канал, в котором мы говорим про искусственный интеллект простыми словами
Главный редактор и по рекламе: @crimeacs
Иногда пишут в канал: @GingerSpacetail, @innovationitsme
Главный редактор и по рекламе: @crimeacs
Иногда пишут в канал: @GingerSpacetail, @innovationitsme
Подписчики
Всего
15 516
Сегодня
0
Просмотров на пост
Всего
2 244
ER
Общий
13.26%
Суточный
10.8%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 1 386 постов
Смотреть все посты
Пост от 28.07.2026 20:15
317
1
8
Выступил в подкасте Паттерн Успеха в IT
Рассказывал про физику и геологию от МГУ до Стэнфорда. Как оказался в центре ИИ бума в Кремниевой долине и куда меня это завело.
В этом выпуске:
• Как попасть в Стэнфорд?
• Чем исследования отличаются от работы в Big Tech?
• Как создаются современные AI-модели
• Что происходит с LLM и AI-агентами прямо сейчас
• Каким будет мир через 5–10 лет
• Почему AI меняет индустрию быстрее, чем большинство людей успевает это осознать
• Стоит ли сегодня строить карьеру в AI
Послушать можно тут
Рассказывал про физику и геологию от МГУ до Стэнфорда. Как оказался в центре ИИ бума в Кремниевой долине и куда меня это завело.
В этом выпуске:
• Как попасть в Стэнфорд?
• Чем исследования отличаются от работы в Big Tech?
• Как создаются современные AI-модели
• Что происходит с LLM и AI-агентами прямо сейчас
• Каким будет мир через 5–10 лет
• Почему AI меняет индустрию быстрее, чем большинство людей успевает это осознать
• Стоит ли сегодня строить карьеру в AI
Послушать можно тут

Пост от 28.07.2026 15:02
892
1
29
YC теперь хочет читать не питч, а то, как вы просите модель починить баг
Привет, у микрофона Ginger.
Пока Артемий едет домой после YC Startup School, я чекнула, что стоит туда попасть.
Мероприятие бесплатное, особо одарённым даже помогают покрыть расходы. Но отбор очень конкурентный: если одного кофаундера приняли, не факт, что поедет второй. В сам YC acceptance rate был 0.5% в 2025, YC Startup School цифр не нашла, но масштаб вы поняли.
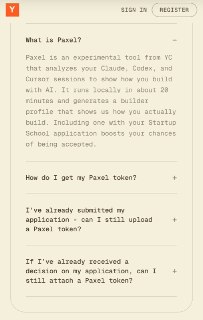
В этом году YC ещё предлагают запустить Paxel — утилиту, которая прошерстит ваши сессии с Claude Code, Codex CLI и Cursor и оценит, что вы за билдер. Опционально, но наличие «Paxel токена» добавляет шансов.
В общем, с Paxel или без, Артемий без преувеличения топ 20% из 30к билдеров мира, подавших заявку, прикиньте?! Спасибо за выжимку докладов, дружище, бесценно!
Но этот пост о другом. Я ж известная ии-совесть. От самой paxel идеи у меня подгорело.
Очень отдает социальным рейтингом и большими этическими вопросами.
Код с машины не уезжает, а вот ваши поведенческие паттерны — да. Транскрипты сессий бьются на чанки и отправляются на YC-шный прокси с gpt-5.5, оттуда возвращаются оценки, и на серверы YC отправляется JSON со скорами, нарративами, решениями и метаданными сессий. Техническую часть Paxel разобрал Sxela, интересное.
Оценивают по пяти осям и шкале 1–10 с текстовыми заметками (ага, там есть вежливость, котятки).
Это буквально скоринг людей с рейтингом и базой на 1.2 миллиона человек, уже отправивших свои json файлики в YC.
Да, именно Этот тул можно (опционально) запустить в один проект. Но нет, в кодинг-сессиях лежат не только красивые рефакторинги. Там лежат NDA, корпоративные секреты, чужие данные, куски инфры про здоровье, финансы, отношения, ментальное состояние и всё, что вы в три ночи вываливали агенту, или о чем можно сделать вывод по косвенным признакам.
Еще, например, под моими акками с моделями общаются и билдят дети. Я намеренно не читаю их диалоги (принцип тот же, что и стучаться перед тем, как зайти в комнату). Мысль о том, что где-то это станет входными данными для чьего-то рейтинга по хз каким критериям, мне не нравится совсем.
Кст, список чувствительных тем, протекающих в наши ллм-сессии продолжайте в комментах — оч интересно.
Без сомнений, что это только первый {заметный} такой проект. Их будет много. “Проанализируем ваших сотрудников”, “профориентируем ваших детей”, “проверим совместимость с партнёром по гороскопу по ЛЛМ-диалогам”, вангую, что в дейтинг что-то такое обязательно прикрутят. Да, @uberkinder? 🤔
Наши диалоги с ЛЛМ — новая нефть.
Но вернемся к Startup School.
Во всей истории с YC мне понравилось, что один чел получил приглашение на startup school 2026, хакнув paxel .
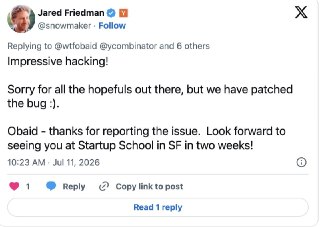
Обайд понимал, что шансы у него не оч (без лиги плюща и вообще без формального образования), и что этичный взлом был бы шорткатом в зал. Нашёл дыру: nonce не подписывал сам результат модели, то есть любой скор можно было подделать и залить в базу YC. Удивился, что получилось, и что никто не попробовал до него.
Написал в YC, спустя 12 дней не получил ответа. Тогда опубликовал в X, и Джаред Фридман (Managing Director YC) ответил через пару часов: спасибо, патч выкатили, ждём в SF. А за те пару часов больше 20 человек успели через его зеркало поставить себе топ-1% в базе YC.
Артемий, когда проснёшься, расскажи, ты запускал Paxel? Если да, было ли в результатах что-то новое, что ты узнал о себе?
А пока у Артемия 4 часа ночи, признавайтесь, вы бы запустили эту строчку?
$ curl -fsSL https://paxel.ycombinator.com/upload.sh | bash
(и нет, пожалуйста, не запускайте по фану чужие однострочники в bash, тем более после всего вышенаписанного)
Сорс:
Obaid
Paxel
Привет, у микрофона Ginger.
Пока Артемий едет домой после YC Startup School, я чекнула, что стоит туда попасть.
Мероприятие бесплатное, особо одарённым даже помогают покрыть расходы. Но отбор очень конкурентный: если одного кофаундера приняли, не факт, что поедет второй. В сам YC acceptance rate был 0.5% в 2025, YC Startup School цифр не нашла, но масштаб вы поняли.
В этом году YC ещё предлагают запустить Paxel — утилиту, которая прошерстит ваши сессии с Claude Code, Codex CLI и Cursor и оценит, что вы за билдер. Опционально, но наличие «Paxel токена» добавляет шансов.
В общем, с Paxel или без, Артемий без преувеличения топ 20% из 30к билдеров мира, подавших заявку, прикиньте?! Спасибо за выжимку докладов, дружище, бесценно!
Но этот пост о другом. Я ж известная ии-совесть. От самой paxel идеи у меня подгорело.
Очень отдает социальным рейтингом и большими этическими вопросами.
Код с машины не уезжает, а вот ваши поведенческие паттерны — да. Транскрипты сессий бьются на чанки и отправляются на YC-шный прокси с gpt-5.5, оттуда возвращаются оценки, и на серверы YC отправляется JSON со скорами, нарративами, решениями и метаданными сессий. Техническую часть Paxel разобрал Sxela, интересное.
Оценивают по пяти осям и шкале 1–10 с текстовыми заметками (ага, там есть вежливость, котятки).
Это буквально скоринг людей с рейтингом и базой на 1.2 миллиона человек, уже отправивших свои json файлики в YC.
Да, именно Этот тул можно (опционально) запустить в один проект. Но нет, в кодинг-сессиях лежат не только красивые рефакторинги. Там лежат NDA, корпоративные секреты, чужие данные, куски инфры про здоровье, финансы, отношения, ментальное состояние и всё, что вы в три ночи вываливали агенту, или о чем можно сделать вывод по косвенным признакам.
Еще, например, под моими акками с моделями общаются и билдят дети. Я намеренно не читаю их диалоги (принцип тот же, что и стучаться перед тем, как зайти в комнату). Мысль о том, что где-то это станет входными данными для чьего-то рейтинга по хз каким критериям, мне не нравится совсем.
Кст, список чувствительных тем, протекающих в наши ллм-сессии продолжайте в комментах — оч интересно.
Без сомнений, что это только первый {заметный} такой проект. Их будет много. “Проанализируем ваших сотрудников”, “профориентируем ваших детей”, “проверим совместимость с партнёром по гороскопу по ЛЛМ-диалогам”, вангую, что в дейтинг что-то такое обязательно прикрутят. Да, @uberkinder? 🤔
Наши диалоги с ЛЛМ — новая нефть.
Но вернемся к Startup School.
Во всей истории с YC мне понравилось, что один чел получил приглашение на startup school 2026, хакнув paxel .
Обайд понимал, что шансы у него не оч (без лиги плюща и вообще без формального образования), и что этичный взлом был бы шорткатом в зал. Нашёл дыру: nonce не подписывал сам результат модели, то есть любой скор можно было подделать и залить в базу YC. Удивился, что получилось, и что никто не попробовал до него.
Написал в YC, спустя 12 дней не получил ответа. Тогда опубликовал в X, и Джаред Фридман (Managing Director YC) ответил через пару часов: спасибо, патч выкатили, ждём в SF. А за те пару часов больше 20 человек успели через его зеркало поставить себе топ-1% в базе YC.
Артемий, когда проснёшься, расскажи, ты запускал Paxel? Если да, было ли в результатах что-то новое, что ты узнал о себе?
А пока у Артемия 4 часа ночи, признавайтесь, вы бы запустили эту строчку?
$ curl -fsSL https://paxel.ycombinator.com/upload.sh | bash
(и нет, пожалуйста, не запускайте по фану чужие однострочники в bash, тем более после всего вышенаписанного)
Сорс:
Obaid
Paxel

😁
5
❤
2
🔥
2
Пост от 27.07.2026 04:20
51
0
8
Главная ошибка AI-стартапов — мыслить слишком мелко
Сэм Альтман на Startup School сформулировал парадокс:
AI позволяет маленькой команде делать то, для чего раньше требовалась целая компания. Но большинство основателей используют эту сверхсилу, чтобы собрать очередную обёртку над ChatGPT.
Если модель за один промпт повторяет продукт, который раньше строили годами, — это не значит, что создавать больше нечего.
Это значит, что нужно взяться за задачу на порядок сложнее.
Несколько мыслей из выступления:
1. Сейчас золотое время для стартапов
Стоимость разработки падает, циклы становятся короче, а доступ к знаниям — почти бесплатным. Несколько человек с AI-агентами могут замахнуться на проекты, которые недавно требовали сотен сотрудников.
2. Лучшие идеи сначала выглядят неправильными
Большие компании редко рождаются из модного консенсуса. Обычно основатель замечает экспоненту или технологический сдвиг, который остальные ещё не успели принять всерьёз.
Но одной «контринтуитивности» недостаточно. Убеждённость должна расти вместе с доказательствами: работающим продуктом, поведением пользователей и реальными результатами.
3. Огромная цель должна начинаться с маленького работающего шага
OpenAI говорил об AGI, но начинал как небольшая исследовательская лаборатория. Большое видение не требует сразу строить всю империю.
Нужно найти минимальный шаг, который проверяет главную гипотезу и создаёт реальное движение вперёд.
4. Связи между основателями накапливаются годами
Альтман рассказал, как когда-то помог Stripe нанять Грега Брокмана — задолго до того, как они вместе основали OpenAI.
Вывод простой: помогать сильным людям полезно без немедленного расчёта на отдачу. Невозможно заранее узнать, во что превратится одна встреча через десять лет.
5. AI должен расширять человеческую свободу, а не только создавать изобилие
Даже мир без болезней и материального дефицита будет антиутопией, если в нём не останется приватности, самостоятельности и осмысленной роли для человека.
Поэтому главный вопрос не только в том, насколько умными станут модели.
А в том, кто контролирует их действия — и сохраняет ли человек право принимать окончательное решение.
Главный вывод: AI резко снизил стоимость амбиции.
Теперь маленькая команда может поставить перед собой почти абсурдно большую цель.
Хочу закончить трансляцию с YC Summer School словами Live in the future, then build what’s missing.
Сэм Альтман на Startup School сформулировал парадокс:
AI позволяет маленькой команде делать то, для чего раньше требовалась целая компания. Но большинство основателей используют эту сверхсилу, чтобы собрать очередную обёртку над ChatGPT.
Если модель за один промпт повторяет продукт, который раньше строили годами, — это не значит, что создавать больше нечего.
Это значит, что нужно взяться за задачу на порядок сложнее.
Несколько мыслей из выступления:
1. Сейчас золотое время для стартапов
Стоимость разработки падает, циклы становятся короче, а доступ к знаниям — почти бесплатным. Несколько человек с AI-агентами могут замахнуться на проекты, которые недавно требовали сотен сотрудников.
2. Лучшие идеи сначала выглядят неправильными
Большие компании редко рождаются из модного консенсуса. Обычно основатель замечает экспоненту или технологический сдвиг, который остальные ещё не успели принять всерьёз.
Но одной «контринтуитивности» недостаточно. Убеждённость должна расти вместе с доказательствами: работающим продуктом, поведением пользователей и реальными результатами.
3. Огромная цель должна начинаться с маленького работающего шага
OpenAI говорил об AGI, но начинал как небольшая исследовательская лаборатория. Большое видение не требует сразу строить всю империю.
Нужно найти минимальный шаг, который проверяет главную гипотезу и создаёт реальное движение вперёд.
4. Связи между основателями накапливаются годами
Альтман рассказал, как когда-то помог Stripe нанять Грега Брокмана — задолго до того, как они вместе основали OpenAI.
Вывод простой: помогать сильным людям полезно без немедленного расчёта на отдачу. Невозможно заранее узнать, во что превратится одна встреча через десять лет.
5. AI должен расширять человеческую свободу, а не только создавать изобилие
Даже мир без болезней и материального дефицита будет антиутопией, если в нём не останется приватности, самостоятельности и осмысленной роли для человека.
Поэтому главный вопрос не только в том, насколько умными станут модели.
А в том, кто контролирует их действия — и сохраняет ли человек право принимать окончательное решение.
Главный вывод: AI резко снизил стоимость амбиции.
Теперь маленькая команда может поставить перед собой почти абсурдно большую цель.
Хочу закончить трансляцию с YC Summer School словами Live in the future, then build what’s missing.

Пост от 27.07.2026 03:21
43
0
9
Как продавать стартап: уроки с живого разбора Пита Казанджи
Кто именно должен купить ваш продукт — и почему ему было бы глупо этого не сделать?
Из нескольких совершенно разных компаний сложилась одна практическая система.
1. Ищите не широкий рынок, а сочетание боли и денег
У стартапа для hardware-команд было три сегмента:
• у небольших компаний есть деньги, но проблема недостаточно острая;
• у академических лабораторий проблема острая, но платить они не хотят;
• у enterprise есть и боль, и бюджет, но длинный цикл продажи и уже внедрённые системы.
Вывод — не выбирать между «маленькими» и «большими» абстрактно. Ищите сегмент, где одновременно присутствуют сильная боль, бюджет и достижимая первая сделка.
2. ICP — это организация плюс конкретный человек внутри неё
Платформа для мероприятий сначала описывала клиента как «компанию, которая проводит события». Это почти бесполезно.
После разбора ICP стал наблюдаемым:
• компания уже успешно проводит крупное ежегодное мероприятие и начинает региональную серию;
• она выросла из Luma/Eventbrite, но ещё не готова к тяжёлому Cvent;
• мероприятия проходят на площадках среднего размера;
• внутри нет полноценной event-команды, поэтому всё свалили на перегруженного EA или field marketer.
Искать таких клиентов можно не только через outbound: площадки, каталоги событий и платформы без onsite-операций становятся каналами дистрибуции.
3. У хорошего ICP есть внешние следы
Производитель лабораторного оборудования находил клиентов по публикациям, грантам и типам экспериментов. Если команда выращивает органоиды или занимается биопечатью, можно предположить конкретное оборудование и высокую стоимость неудачного эксперимента.
Вместо общего письма «мы автоматизируем лаборатории» можно прийти с гипотезой.
Сильный outbound начинается не со списка должностей, а с «выхлопа» реальной работы клиента: публикаций, вакансий, новых проектов, мероприятий, грантов, технологий и партнёрств.
4. Экономику нужно измерять, а не придумывать
AI-брокер по перевозке автомобилей говорил, что он значительно дешевле традиционных посредников. Но подтверждён был только один маршрут: конкурент взял бы около $1 300 комиссии, а стартап — около $300. Реальная экономия на этой перевозке составляла примерно $1 000.
Это уже сильное доказательство. Но из одного случая нельзя честно сделать заявление «экономим 75% ежемесячно».
Сначала измерьте результат у первого хорошего клиента. Затем используйте его имя, объём, скорость и подтверждённую экономию, чтобы продавать похожим компаниям из той же сети.
5. Не бойтесь ручной работы до того, как нашли повторяемую продажу
Другой стартап резко повышал эффективность рекламы брендов, продающих через Amazon, но клиенты отваливались на сложной установке пикселей и интеграций.
Ответ Казанджи был предельно простой: настройте всё за клиента и возьмите отдельную плату за onboarding.
«Это не масштабируется» — преждевременный страх.
6. В enterprise продавайте не замену системы, а маленький greenfield-проект
Молодой компании трудно убедить корпорацию выбросить уже внедрённую платформу. Намного проще войти через новый проект, команду или workflow, где ещё нечего заменять.
Так MongoDB исторически было легче попасть в новую application, чем убедить компанию перенести все базы данных сразу.
Правильный первый контракт уменьшает не только цену, но и необходимый уровень доверия.
Главный вывод воркшопа:
Founder-led sales — это не когда основатель навсегда становится продавцом. Это период, когда он лично выясняет, кто покупает, из-за какой боли, по какому сигналу, с каким доказательством и через какую маленькую первую сделку.
Нанимать отдел продаж стоит после того, как эти ответы стали повторяемыми. До этого момента продажи нельзя делегировать — потому что вы ещё не знаете, что именно нужно повторять.
Кто именно должен купить ваш продукт — и почему ему было бы глупо этого не сделать?
Из нескольких совершенно разных компаний сложилась одна практическая система.
1. Ищите не широкий рынок, а сочетание боли и денег
У стартапа для hardware-команд было три сегмента:
• у небольших компаний есть деньги, но проблема недостаточно острая;
• у академических лабораторий проблема острая, но платить они не хотят;
• у enterprise есть и боль, и бюджет, но длинный цикл продажи и уже внедрённые системы.
Вывод — не выбирать между «маленькими» и «большими» абстрактно. Ищите сегмент, где одновременно присутствуют сильная боль, бюджет и достижимая первая сделка.
2. ICP — это организация плюс конкретный человек внутри неё
Платформа для мероприятий сначала описывала клиента как «компанию, которая проводит события». Это почти бесполезно.
После разбора ICP стал наблюдаемым:
• компания уже успешно проводит крупное ежегодное мероприятие и начинает региональную серию;
• она выросла из Luma/Eventbrite, но ещё не готова к тяжёлому Cvent;
• мероприятия проходят на площадках среднего размера;
• внутри нет полноценной event-команды, поэтому всё свалили на перегруженного EA или field marketer.
Искать таких клиентов можно не только через outbound: площадки, каталоги событий и платформы без onsite-операций становятся каналами дистрибуции.
3. У хорошего ICP есть внешние следы
Производитель лабораторного оборудования находил клиентов по публикациям, грантам и типам экспериментов. Если команда выращивает органоиды или занимается биопечатью, можно предположить конкретное оборудование и высокую стоимость неудачного эксперимента.
Вместо общего письма «мы автоматизируем лаборатории» можно прийти с гипотезой.
Сильный outbound начинается не со списка должностей, а с «выхлопа» реальной работы клиента: публикаций, вакансий, новых проектов, мероприятий, грантов, технологий и партнёрств.
4. Экономику нужно измерять, а не придумывать
AI-брокер по перевозке автомобилей говорил, что он значительно дешевле традиционных посредников. Но подтверждён был только один маршрут: конкурент взял бы около $1 300 комиссии, а стартап — около $300. Реальная экономия на этой перевозке составляла примерно $1 000.
Это уже сильное доказательство. Но из одного случая нельзя честно сделать заявление «экономим 75% ежемесячно».
Сначала измерьте результат у первого хорошего клиента. Затем используйте его имя, объём, скорость и подтверждённую экономию, чтобы продавать похожим компаниям из той же сети.
5. Не бойтесь ручной работы до того, как нашли повторяемую продажу
Другой стартап резко повышал эффективность рекламы брендов, продающих через Amazon, но клиенты отваливались на сложной установке пикселей и интеграций.
Ответ Казанджи был предельно простой: настройте всё за клиента и возьмите отдельную плату за onboarding.
«Это не масштабируется» — преждевременный страх.
6. В enterprise продавайте не замену системы, а маленький greenfield-проект
Молодой компании трудно убедить корпорацию выбросить уже внедрённую платформу. Намного проще войти через новый проект, команду или workflow, где ещё нечего заменять.
Так MongoDB исторически было легче попасть в новую application, чем убедить компанию перенести все базы данных сразу.
Правильный первый контракт уменьшает не только цену, но и необходимый уровень доверия.
Главный вывод воркшопа:
Founder-led sales — это не когда основатель навсегда становится продавцом. Это период, когда он лично выясняет, кто покупает, из-за какой боли, по какому сигналу, с каким доказательством и через какую маленькую первую сделку.
Нанимать отдел продаж стоит после того, как эти ответы стали повторяемыми. До этого момента продажи нельзя делегировать — потому что вы ещё не знаете, что именно нужно повторять.

Пост от 27.07.2026 01:19
173
1
11
Как ClawFather построил OpenClaw.
Питер Штайнбергер начал OpenClaw не с идеи «создать платформу для агентов», а с личного раздражения: он хотел отправлять задачи компьютеру с телефона. Первый прототип просто связывал WhatsApp с ноутбуком.
Но именно в этот момент агент перестал ощущаться как чат. Он получил доступ к реальному компьютеру, начал выполнять действия и иногда удивлять результатом. Первыми пользователями стали друзья, затем появился Discord, сообщество и стремительный рост проекта.
Главный вывод из выступления: ценность агента определяется не только моделью. Нужна среда, в которой он способен долго работать:
• сохранять контекст между сессиями;
• самостоятельно просыпаться по событиям;
• пользоваться инструментами;
• выполнять крупные задачи до результата;
• работать с голосом и другими форматами;
• переживать смену поставщика моделей;
• оставаться управляемым по стоимости и риску.
Отсюда и важная формула Питера:
> Your dependency business model is your business model.
Если продукт зависит от одного поставщика модели, он наследует его цены, ограничения, политику и внезапные изменения доступа. OpenClaw изначально был сильно оптимизирован под Claude Opus, поэтому изменения со стороны Anthropic болезненно ударили по продукту.
Есть и менее заметная проблема — экономика «всегда включенного» агента. Питер рассказал, что после истечения KV-кэша один heartbeat мог повторно отправить около 600 тысяч токенов. Поэтому настоящий always-on агент — это не бесконечно работающая модель, а грамотно спроектированная система событий, памяти, сжатия контекста и ограниченных запусков.
Еще один сильный сигнал — инфраструктура. Локальные тесты быстро занимают все доступные ресурсы, а единой удобной среды для переноса агентных нагрузок между Linux, macOS, Windows и облаком пока нет. Собственным парком машин Питер управляет вручную и прямо признает, что не должен тратить на это время.
Питер Штайнбергер начал OpenClaw не с идеи «создать платформу для агентов», а с личного раздражения: он хотел отправлять задачи компьютеру с телефона. Первый прототип просто связывал WhatsApp с ноутбуком.
Но именно в этот момент агент перестал ощущаться как чат. Он получил доступ к реальному компьютеру, начал выполнять действия и иногда удивлять результатом. Первыми пользователями стали друзья, затем появился Discord, сообщество и стремительный рост проекта.
Главный вывод из выступления: ценность агента определяется не только моделью. Нужна среда, в которой он способен долго работать:
• сохранять контекст между сессиями;
• самостоятельно просыпаться по событиям;
• пользоваться инструментами;
• выполнять крупные задачи до результата;
• работать с голосом и другими форматами;
• переживать смену поставщика моделей;
• оставаться управляемым по стоимости и риску.
Отсюда и важная формула Питера:
> Your dependency business model is your business model.
Если продукт зависит от одного поставщика модели, он наследует его цены, ограничения, политику и внезапные изменения доступа. OpenClaw изначально был сильно оптимизирован под Claude Opus, поэтому изменения со стороны Anthropic болезненно ударили по продукту.
Есть и менее заметная проблема — экономика «всегда включенного» агента. Питер рассказал, что после истечения KV-кэша один heartbeat мог повторно отправить около 600 тысяч токенов. Поэтому настоящий always-on агент — это не бесконечно работающая модель, а грамотно спроектированная система событий, памяти, сжатия контекста и ограниченных запусков.
Еще один сильный сигнал — инфраструктура. Локальные тесты быстро занимают все доступные ресурсы, а единой удобной среды для переноса агентных нагрузок между Linux, macOS, Windows и облаком пока нет. Собственным парком машин Питер управляет вручную и прямо признает, что не должен тратить на это время.

Пост от 27.07.2026 00:17
1
0
0
Александr Ванг: в AI выигрывает не тот, у кого самая новая модель
На Startup School 2026 основатель Scale AI и руководитель AI-направления Meta Александr Ванг говорил о том, как строить компании, когда технологический фронтир меняется буквально каждый месяц.
Главная мысль: нельзя привязывать компанию к возможностям конкретной модели. Сегодняшнее преимущество быстро становится стандартной функцией. Поэтому продукт стоит строить вокруг устойчивой проблемы клиента, предполагая, что модели, цены и доступные возможности постоянно будут меняться.
Следующее узкое место AI — уже не только интеллект модели. Всё большее значение имеют данные, evals, обратная связь, инфраструктура и способность превращать вероятностный ответ в стабильно полезный результат.
Отсюда практический вывод: лучший способ учиться — как можно раньше внедрять продукт в реальную работу. Смотреть, где он ошибается, собирать сложные случаи и возвращать их в цикл улучшения. Ожидание «идеальной модели» лишь откладывает получение самой ценной информации.
Ванг также сделал акцент на плотности таланта и прямой ответственности. Небольшая команда сильных людей с ясной зоной владения может двигаться быстрее крупной организации, где энергия уходит на согласования.
И наконец, удешевление разработки должно увеличивать амбиции основателей. Если создать продукт стало проще, это не повод выпускать ещё одну тонкую оболочку над моделью. Это возможность взяться за более трудную и значимую проблему.
На Startup School 2026 основатель Scale AI и руководитель AI-направления Meta Александr Ванг говорил о том, как строить компании, когда технологический фронтир меняется буквально каждый месяц.
Главная мысль: нельзя привязывать компанию к возможностям конкретной модели. Сегодняшнее преимущество быстро становится стандартной функцией. Поэтому продукт стоит строить вокруг устойчивой проблемы клиента, предполагая, что модели, цены и доступные возможности постоянно будут меняться.
Следующее узкое место AI — уже не только интеллект модели. Всё большее значение имеют данные, evals, обратная связь, инфраструктура и способность превращать вероятностный ответ в стабильно полезный результат.
Отсюда практический вывод: лучший способ учиться — как можно раньше внедрять продукт в реальную работу. Смотреть, где он ошибается, собирать сложные случаи и возвращать их в цикл улучшения. Ожидание «идеальной модели» лишь откладывает получение самой ценной информации.
Ванг также сделал акцент на плотности таланта и прямой ответственности. Небольшая команда сильных людей с ясной зоной владения может двигаться быстрее крупной организации, где энергия уходит на согласования.
И наконец, удешевление разработки должно увеличивать амбиции основателей. Если создать продукт стало проще, это не повод выпускать ещё одну тонкую оболочку над моделью. Это возможность взяться за более трудную и значимую проблему.

Пост от 26.07.2026 23:30
795
5
17
День 2. Патрик Коллисон на Startup School
Второй день начался с разговора Патрика Коллисона, сооснователя и CEO Stripe, и Харжа Тага́ра.
Сначала говорили о том, чему стоит учиться в эпоху AI. Коллисон сравнил знания в голове с L1-кэшем компьютера: даже если модель способна найти или вычислить ответ, уже усвоенное человеком знание доступно быстрее и позволяет совершать больше мыслительных итераций. По его словам, способность программировать, рассуждать, писать и ясно общаться по-прежнему высоко ценится. Сам он пока не использует автоматически сгенерированные ответы в почте и мессенджерах и считает человеческое письмо более точным и содержательным.
Затем разговор перешёл к учёбе и основанию компаний. Коллисон дважды уходил из университета ради стартапов и возвращался обратно. Он сказал, что бросать колледж необязательно: если человеку нравится учиться, нет ничего плохого в том, чтобы закончить образование. При этом уход из университета не является необратимым решением и, по его опыту, впоследствии почти никого не интересовал.
Коллисон также предостерёг студентов от идеи, что нынешний момент — последняя возможность создать компанию и избежать будущего «постоянного низшего класса». По его словам, люди регулярно воспринимают новые технологии как окончательное переустройство общества, но предпринимательские возможности в Кремниевой долине продолжают появляться десятилетиями.
Stripe родился после Startup School 2009 года. После мероприятия Патрик и Джон Коллисоны пошли за суши, а по дороге решили начать работать над платежной компанией. Они предполагали, что проект займет несколько месяцев; прошло почти 17 лет.
Идея Stripe казалась одновременно очевидной и неправдоподобной. Интернет-платежи были сложными и неудобными, но банки и партнеры с трудом воспринимали двух молодых основателей как серьезную финансовую компанию. По словам Коллисона, их удерживала конкретная проблема, которую пользователи действительно испытывали и хотели решить.
До публичного запуска Stripe прошло почти два года. Коллисон объяснил это требованиями к безопасности, банковским партнерам, движению денег, инфраструктуре и надежности. При этом компания не строила продукт в изоляции: первый реальный пользователь появился примерно через два месяца после начала работы. Функции добавлялись вслед за его запросами — просмотр платежей, возвраты и вывод средств. Число пользователей затем увеличивалось каждый месяц до публичного запуска.
Обсуждая стартапы в эпоху AI, Коллисон предположил, что прежний подход с поиском маленькой свободной ниши может стать более конкурентным. Поскольку создавать программное обеспечение стало дешевле, основателям, возможно, придется выбирать более амбициозные и менее очевидные направления.
Еще один его совет — думать не только о возможном провале, но и об успехе. Перед привлечением значительного капитала основателю стоит спросить себя, хочет ли он заниматься этой компанией 10, 17 или 30 лет. В любом бизнесе будет много рутинной работы, поэтому важна привлекательность всей области и долгосрочной миссии, а не только отдельных интересных задач.
Коллисон также не согласился с тем, что несколько крупных AI-лабораторий заберут всю экономическую ценность. Он привел исторический пример Google: даже организация с выдающимися специалистами, капиталом и инфраструктурой не может одновременно реализовать все возможные направления. По его ожиданиям, AI создаст не только несколько крупных победителей, но и тысячи новых компаний.
В заключение Коллисон поделился наблюдениями из данных Stripe. По его словам, число новых компаний на платформе выросло почти вдвое год к году — это один из крупнейших скачков, которые они наблюдали. При этом медианный новый бизнес работает лучше, чем год назад, а компании быстрее достигают первых уровней выручки.
Второй день начался с разговора Патрика Коллисона, сооснователя и CEO Stripe, и Харжа Тага́ра.
Сначала говорили о том, чему стоит учиться в эпоху AI. Коллисон сравнил знания в голове с L1-кэшем компьютера: даже если модель способна найти или вычислить ответ, уже усвоенное человеком знание доступно быстрее и позволяет совершать больше мыслительных итераций. По его словам, способность программировать, рассуждать, писать и ясно общаться по-прежнему высоко ценится. Сам он пока не использует автоматически сгенерированные ответы в почте и мессенджерах и считает человеческое письмо более точным и содержательным.
Затем разговор перешёл к учёбе и основанию компаний. Коллисон дважды уходил из университета ради стартапов и возвращался обратно. Он сказал, что бросать колледж необязательно: если человеку нравится учиться, нет ничего плохого в том, чтобы закончить образование. При этом уход из университета не является необратимым решением и, по его опыту, впоследствии почти никого не интересовал.
Коллисон также предостерёг студентов от идеи, что нынешний момент — последняя возможность создать компанию и избежать будущего «постоянного низшего класса». По его словам, люди регулярно воспринимают новые технологии как окончательное переустройство общества, но предпринимательские возможности в Кремниевой долине продолжают появляться десятилетиями.
Stripe родился после Startup School 2009 года. После мероприятия Патрик и Джон Коллисоны пошли за суши, а по дороге решили начать работать над платежной компанией. Они предполагали, что проект займет несколько месяцев; прошло почти 17 лет.
Идея Stripe казалась одновременно очевидной и неправдоподобной. Интернет-платежи были сложными и неудобными, но банки и партнеры с трудом воспринимали двух молодых основателей как серьезную финансовую компанию. По словам Коллисона, их удерживала конкретная проблема, которую пользователи действительно испытывали и хотели решить.
До публичного запуска Stripe прошло почти два года. Коллисон объяснил это требованиями к безопасности, банковским партнерам, движению денег, инфраструктуре и надежности. При этом компания не строила продукт в изоляции: первый реальный пользователь появился примерно через два месяца после начала работы. Функции добавлялись вслед за его запросами — просмотр платежей, возвраты и вывод средств. Число пользователей затем увеличивалось каждый месяц до публичного запуска.
Обсуждая стартапы в эпоху AI, Коллисон предположил, что прежний подход с поиском маленькой свободной ниши может стать более конкурентным. Поскольку создавать программное обеспечение стало дешевле, основателям, возможно, придется выбирать более амбициозные и менее очевидные направления.
Еще один его совет — думать не только о возможном провале, но и об успехе. Перед привлечением значительного капитала основателю стоит спросить себя, хочет ли он заниматься этой компанией 10, 17 или 30 лет. В любом бизнесе будет много рутинной работы, поэтому важна привлекательность всей области и долгосрочной миссии, а не только отдельных интересных задач.
Коллисон также не согласился с тем, что несколько крупных AI-лабораторий заберут всю экономическую ценность. Он привел исторический пример Google: даже организация с выдающимися специалистами, капиталом и инфраструктурой не может одновременно реализовать все возможные направления. По его ожиданиям, AI создаст не только несколько крупных победителей, но и тысячи новых компаний.
В заключение Коллисон поделился наблюдениями из данных Stripe. По его словам, число новых компаний на платформе выросло почти вдвое год к году — это один из крупнейших скачков, которые они наблюдали. При этом медианный новый бизнес работает лучше, чем год назад, а компании быстрее достигают первых уровней выручки.
