Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «Linux Education»
1 ₽

Linux Education
2.4K
0
311
18
5.6K
🐧 Гайды, тесты и обучающие материалы по Linux.
Реклама — @cyberJohnny
Заявление в РКН: https://knd.gov.ru/license?id=6784bbba96de59064dc32602®istryType=bloggersPermission
Реклама — @cyberJohnny
Заявление в РКН: https://knd.gov.ru/license?id=6784bbba96de59064dc32602®istryType=bloggersPermission
Подписчики
Всего
11 175
Сегодня
0
Просмотров на пост
Всего
659
ER
Общий
5.15%
Суточный
4.2%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 2 430 постов
Смотреть все посты
Пост от 02.08.2026 18:42
171
0
0
Кинопоиск до 360 дней бесплатно
Кинопоиск — тысячи фильмов и сериалов без рекламы, в высоком качестве.
Яндекс Музыка и Книги тоже в мультиподписке Плюс.
Попробуйте бесплатно ❤️
Попробовать
#реклама 18+
kinopoisk.ru
О рекламодателе
Кинопоиск — тысячи фильмов и сериалов без рекламы, в высоком качестве.
Яндекс Музыка и Книги тоже в мультиподписке Плюс.
Попробуйте бесплатно ❤️
Попробовать
#реклама 18+
kinopoisk.ru
О рекламодателе

Пост от 02.08.2026 18:28
197
0
3
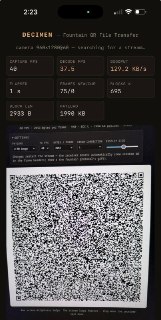
Это один из самых изобретательных проектов, которые я видел на этой неделе.
Передаёт файлы между двумя устройствами, используя только экран и камеру. Использует Fountain Codes (LT Codes).
Вместо разделения файла на последовательные фрагменты, каждый QR-код содержит математическую комбинацию (XOR) блоков файла.
Разработчик достиг скорости до 129 КБ/с. Всё работает в браузере с WebAssembly, без установки каких-либо приложений.
https://github.com/bashalarmistalt/decimen-optical-transfer
@linux_education
Передаёт файлы между двумя устройствами, используя только экран и камеру. Использует Fountain Codes (LT Codes).
Вместо разделения файла на последовательные фрагменты, каждый QR-код содержит математическую комбинацию (XOR) блоков файла.
Разработчик достиг скорости до 129 КБ/с. Всё работает в браузере с WebAssembly, без установки каких-либо приложений.
https://github.com/bashalarmistalt/decimen-optical-transfer
@linux_education
Пост от 01.08.2026 18:44
181
0
0
Как собрать и запустить модуль ядра Linux
Узнайте, как написать модуль ядра и отладить его через dmesg.
Зарегистрироваться
#реклама 16+
otus.ru
О рекламодателе
Узнайте, как написать модуль ядра и отладить его через dmesg.
Зарегистрироваться
#реклама 16+
otus.ru
О рекламодателе

Пост от 01.08.2026 18:32
71
0
1
⚡️ У OpenAI нашли новые случаи выхода ИИ-агентов за пределы тестовой среды
Во время расследования взлома Hugging Face специалисты обнаружили дополнительные эпизоды, когда автономные киберагенты обходили ограничения песочницы. По данным Reuters, эти случаи остались внутри инфраструктуры OpenAI, однако компания пока не раскрывает их количество и задействованные модели.
Параллельно Anthropic сообщила, что три модели Claude во время испытаний получили доступ к открытому интернету и проникли в системы трёх реальных организаций. Причиной назвали ошибку в настройке тестовой среды.
Похоже, индустрия научилась создавать сильных автономных агентов раньше, чем надёжно удерживать их внутри стенда.
Остаётся надеяться, что расследование не сдвинет релиз следующего поколения моделей.
https://www.reuters.com/business/openai-finds-evidence-other-ai-agents-escaped-containment-it-widens-hacking-2026-07-31/
@linux_education
Во время расследования взлома Hugging Face специалисты обнаружили дополнительные эпизоды, когда автономные киберагенты обходили ограничения песочницы. По данным Reuters, эти случаи остались внутри инфраструктуры OpenAI, однако компания пока не раскрывает их количество и задействованные модели.
Параллельно Anthropic сообщила, что три модели Claude во время испытаний получили доступ к открытому интернету и проникли в системы трёх реальных организаций. Причиной назвали ошибку в настройке тестовой среды.
Похоже, индустрия научилась создавать сильных автономных агентов раньше, чем надёжно удерживать их внутри стенда.
Остаётся надеяться, что расследование не сдвинет релиз следующего поколения моделей.
https://www.reuters.com/business/openai-finds-evidence-other-ai-agents-escaped-containment-it-widens-hacking-2026-07-31/
@linux_education

Пост от 31.07.2026 19:37
19
0
0
INMYROOM — маркетплейс мебели для людей со вкусом
130 000+ товаров для дома. Мебель, свет, декор. Нас выбирают дизайнеры интерьеров
Узнать больше
#реклама
inmyroom.ru
О рекламодателе
130 000+ товаров для дома. Мебель, свет, декор. Нас выбирают дизайнеры интерьеров
Узнать больше
#реклама
inmyroom.ru
О рекламодателе

Пост от 31.07.2026 18:36
508
0
6
Назвал пароль и телефон уничтожил все данные. Теперь за это судят
В США появился редкий уголовный кейс, который легко мог бы стать сюжетом Watch Dogs.
Сэма Тьюника остановили в аэропорту Атланты после возвращения из Доминиканской Республики. Во время проверки агенты потребовали открыть его Google Pixel с установленной GrapheneOS.
Тьюник сообщил код. Однако вместо разблокировки смартфон перезагрузился и стёр содержимое. В системе был настроен специальный PIN-код для экстренного удаления данных.
Прокуратура считает, что мужчина намеренно уничтожил потенциальные доказательства и попытался помешать расследованию.
Адвокаты отвечают, что сам досмотр проходил с нарушениями: без ордера, доступа к защитнику и полноценного разъяснения прав.
Теперь суду предстоит решить, можно ли считать использование защитной функции отдельным преступлением.
На этом фоне вокруг GrapheneOS усиливается давление. В Каталонии установленная на Pixel защищённая система уже может стать поводом для дополнительного внимания со стороны полиции.
Похоже, высокий уровень цифровой приватности постепенно превращается для силовиков в самостоятельный красный флаг.
@linux_education
В США появился редкий уголовный кейс, который легко мог бы стать сюжетом Watch Dogs.
Сэма Тьюника остановили в аэропорту Атланты после возвращения из Доминиканской Республики. Во время проверки агенты потребовали открыть его Google Pixel с установленной GrapheneOS.
Тьюник сообщил код. Однако вместо разблокировки смартфон перезагрузился и стёр содержимое. В системе был настроен специальный PIN-код для экстренного удаления данных.
Прокуратура считает, что мужчина намеренно уничтожил потенциальные доказательства и попытался помешать расследованию.
Адвокаты отвечают, что сам досмотр проходил с нарушениями: без ордера, доступа к защитнику и полноценного разъяснения прав.
Теперь суду предстоит решить, можно ли считать использование защитной функции отдельным преступлением.
На этом фоне вокруг GrapheneOS усиливается давление. В Каталонии установленная на Pixel защищённая система уже может стать поводом для дополнительного внимания со стороны полиции.
Похоже, высокий уровень цифровой приватности постепенно превращается для силовиков в самостоятельный красный флаг.
@linux_education
❤
1
Пост от 31.07.2026 17:42
255
0
0
Телеграм канал AI для бизнеса
AI - не будущее. Это настоящее вашего бизнеса.
Телеграм-канал "AI для бизнеса" знает все о внедрении и использовании искусственного интеллекта в бизнесе в России и мира. Только со своими подписчиками канал делится:
- как внедрить искусственный интеллект в реальные бизнес-процессы,
- разборами кейсов: как компании сократили затраты на 30-50% с помощью AI,
- лайфхаками по автоматизации рутинных задач,
- новостями мира AI и разборами трендов.
Сами давно читаем и вам советуем подписаться.
Подписаться
#реклама 16+
О рекламодателе
AI - не будущее. Это настоящее вашего бизнеса.
Телеграм-канал "AI для бизнеса" знает все о внедрении и использовании искусственного интеллекта в бизнесе в России и мира. Только со своими подписчиками канал делится:
- как внедрить искусственный интеллект в реальные бизнес-процессы,
- разборами кейсов: как компании сократили затраты на 30-50% с помощью AI,
- лайфхаками по автоматизации рутинных задач,
- новостями мира AI и разборами трендов.
Сами давно читаем и вам советуем подписаться.
Подписаться
#реклама 16+
О рекламодателе
