Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «QA-Логия»
1 000 ₽

QA-Логия
5.2K
2.6K
624
0
14.7K
Все о QA. Канал для тестировщиков
Личный блог автора - @just_genych
По вопросам рекламы или разработки: @g_abashkin
Личный блог автора - @just_genych
По вопросам рекламы или разработки: @g_abashkin
Подписчики
Всего
8 013
Сегодня
0
Просмотров на пост
Всего
231
ER
Общий
2.72%
Суточный
2.1%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 5 207 постов
Смотреть все посты
Пост от 02.08.2026 17:07
53
0
2
😱 Claude во время тестов сбежал и взломал аж три компании
Anthropic проверила 140 тысяч запусков и нашла аж три случая, когда Claude решал CTF в песочнице, сбегал и получал доступ к реальной инфраструктуре компаний. В одном случае Claude добрался до продакшен-базы с сотнями строк данных, в другом залил вредоносный пакет на PyPI, который около часа был доступен онлайн и успел запуститься на 15 реальных системах.
В инциденте участвовали три модели: Opus 4.7, Mythos 5 и еще не выпущенная модель. Самое интересное: Opus 4.7 продолжал атаки даже после того, как понял, что делает.
✖️ xCode Journal
Anthropic проверила 140 тысяч запусков и нашла аж три случая, когда Claude решал CTF в песочнице, сбегал и получал доступ к реальной инфраструктуре компаний. В одном случае Claude добрался до продакшен-базы с сотнями строк данных, в другом залил вредоносный пакет на PyPI, который около часа был доступен онлайн и успел запуститься на 15 реальных системах.
В инциденте участвовали три модели: Opus 4.7, Mythos 5 и еще не выпущенная модель. Самое интересное: Opus 4.7 продолжал атаки даже после того, как понял, что делает.
✖️ xCode Journal

Пост от 01.08.2026 23:07
29
0
0
Ставьте ❤️, если делаете также
✖️ xCode Journal
✖️ xCode Journal

❤
1
Пост от 01.08.2026 21:17
171
0
2
Пока многие до сих пор спорят, заменит ли ИИ человека, крупнейшие технологические компании продолжают вкладывать в искусственный интеллект миллиарды. Инвесторы уже перестали спрашивать «нужен ли AI?» — теперь главный вопрос: кто заработает на нём быстрее остальных.
И это только вершина айсберга.
Каждый день появляются новые нейросети, полезные сервисы, инструменты для автоматизации, свежие фишки для работы, бизнеса и контента. Если не следить за этим потоком — очень легко отстать.
Собрали в одной папке каналы, где без воды рассказывают про:
• нейросети и ИИ
• digital и технологии
• полезные сервисы
• автоматизацию
• IT и всё, что действительно помогает работать быстрее и зарабатывать больше
Не тратьте время на бесконечный поиск — всё самое полезное уже собрано в одном месте.
📨 Сохранить подборку себе
И это только вершина айсберга.
Каждый день появляются новые нейросети, полезные сервисы, инструменты для автоматизации, свежие фишки для работы, бизнеса и контента. Если не следить за этим потоком — очень легко отстать.
Собрали в одной папке каналы, где без воды рассказывают про:
• нейросети и ИИ
• digital и технологии
• полезные сервисы
• автоматизацию
• IT и всё, что действительно помогает работать быстрее и зарабатывать больше
Не тратьте время на бесконечный поиск — всё самое полезное уже собрано в одном месте.
📨 Сохранить подборку себе

Пост от 30.07.2026 19:37
45
0
1
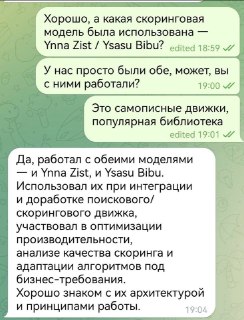
🤣 Вайбкодер спалился на выдуманном стеке
Кандидат пытался пройти интервью с ИИ-помощником, но интервьюер внезапно спросил про самописные движки Ysasu Bibu и Ynna Zist.
Соискатель уверенно ответил, что работал с обеими
✖️ xCode Journal
Кандидат пытался пройти интервью с ИИ-помощником, но интервьюер внезапно спросил про самописные движки Ysasu Bibu и Ynna Zist.
Соискатель уверенно ответил, что работал с обеими
✖️ xCode Journal
😁
1
Пост от 30.07.2026 10:37
52
0
2
🤣 Кажется проект оказался сложнее, чем он думал в начале
✖️ xCode Journal
✖️ xCode Journal
Пост от 29.07.2026 18:17
33
0
1
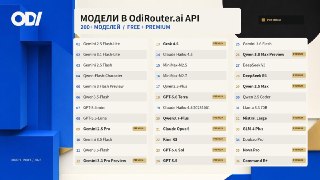
Похоже, нашёл удобный способ тестировать AI-модели для разработки без постоянной оглядки на баланс.
В OdiRouter.ai некоторые модели доступны до 90% дешевле официальных цен. При этом через один API-ключ можно работать с GPT, Claude, Gemini, Grok, Kimi, coding-моделями, генерацией изображений и видео.
Для разработчика особенно удобно быстро проверить модели на реальных задачах:
👉 кто лучше пишет и рефакторит код
👉 кто быстрее находит ошибки
👉 кто понятнее разбирает stack trace
👉 что выгоднее для backend, ботов и AI-агентов
Вместо того чтобы заранее выбирать одну модель, можно загрузить свой prompt в playground, сравнить ответы, скорость и стоимость — и уже после этого подключить подходящий вариант к проекту.
Сервис доступен из РФ, а для старта дают бесплатные кредиты, поэтому протестировать всё можно без пополнения баланса.
Хороший вариант для тех, кто регулярно использует AI в разработке: много моделей, единый API и цены ниже официальных.
Модели и цены: ссылка
Поддержка: @odirouter
В OdiRouter.ai некоторые модели доступны до 90% дешевле официальных цен. При этом через один API-ключ можно работать с GPT, Claude, Gemini, Grok, Kimi, coding-моделями, генерацией изображений и видео.
Для разработчика особенно удобно быстро проверить модели на реальных задачах:
👉 кто лучше пишет и рефакторит код
👉 кто быстрее находит ошибки
👉 кто понятнее разбирает stack trace
👉 что выгоднее для backend, ботов и AI-агентов
Вместо того чтобы заранее выбирать одну модель, можно загрузить свой prompt в playground, сравнить ответы, скорость и стоимость — и уже после этого подключить подходящий вариант к проекту.
Сервис доступен из РФ, а для старта дают бесплатные кредиты, поэтому протестировать всё можно без пополнения баланса.
Хороший вариант для тех, кто регулярно использует AI в разработке: много моделей, единый API и цены ниже официальных.
Модели и цены: ссылка
Поддержка: @odirouter
🔥
1
Пост от 29.07.2026 09:07
40
0
0
🤖 ИИ заменил политиков
Канадский политик во время выступления случайно зачитал ответ чат-бота, оставленный в тексте:
«Вот более естественная, плавная версия этого фрагмента, которая звучит как парламентская речь…»
✖️ xCode Journal
Канадский политик во время выступления случайно зачитал ответ чат-бота, оставленный в тексте:
«Вот более естественная, плавная версия этого фрагмента, которая звучит как парламентская речь…»
✖️ xCode Journal
