Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «QA-Логия»
1 000 ₽

QA-Логия
5.2K
2.6K
624
0
14.7K
Все о QA. Канал для тестировщиков
Личный блог автора - @just_genych
По вопросам рекламы или разработки: @g_abashkin
Личный блог автора - @just_genych
По вопросам рекламы или разработки: @g_abashkin
Подписчики
Всего
8 005
Сегодня
0
Просмотров на пост
Всего
201
ER
Общий
2.33%
Суточный
1.5%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 5 202 постов
Смотреть все посты
Пост от 29.07.2026 18:17
28
0
1
Похоже, нашёл удобный способ тестировать AI-модели для разработки без постоянной оглядки на баланс.
В OdiRouter.ai некоторые модели доступны до 90% дешевле официальных цен. При этом через один API-ключ можно работать с GPT, Claude, Gemini, Grok, Kimi, coding-моделями, генерацией изображений и видео.
Для разработчика особенно удобно быстро проверить модели на реальных задачах:
👉 кто лучше пишет и рефакторит код
👉 кто быстрее находит ошибки
👉 кто понятнее разбирает stack trace
👉 что выгоднее для backend, ботов и AI-агентов
Вместо того чтобы заранее выбирать одну модель, можно загрузить свой prompt в playground, сравнить ответы, скорость и стоимость — и уже после этого подключить подходящий вариант к проекту.
Сервис доступен из РФ, а для старта дают бесплатные кредиты, поэтому протестировать всё можно без пополнения баланса.
Хороший вариант для тех, кто регулярно использует AI в разработке: много моделей, единый API и цены ниже официальных.
Модели и цены: ссылка
Поддержка: @odirouter
В OdiRouter.ai некоторые модели доступны до 90% дешевле официальных цен. При этом через один API-ключ можно работать с GPT, Claude, Gemini, Grok, Kimi, coding-моделями, генерацией изображений и видео.
Для разработчика особенно удобно быстро проверить модели на реальных задачах:
👉 кто лучше пишет и рефакторит код
👉 кто быстрее находит ошибки
👉 кто понятнее разбирает stack trace
👉 что выгоднее для backend, ботов и AI-агентов
Вместо того чтобы заранее выбирать одну модель, можно загрузить свой prompt в playground, сравнить ответы, скорость и стоимость — и уже после этого подключить подходящий вариант к проекту.
Сервис доступен из РФ, а для старта дают бесплатные кредиты, поэтому протестировать всё можно без пополнения баланса.
Хороший вариант для тех, кто регулярно использует AI в разработке: много моделей, единый API и цены ниже официальных.
Модели и цены: ссылка
Поддержка: @odirouter
Пост от 29.07.2026 09:07
40
0
0
🤖 ИИ заменил политиков
Канадский политик во время выступления случайно зачитал ответ чат-бота, оставленный в тексте:
«Вот более естественная, плавная версия этого фрагмента, которая звучит как парламентская речь…»
✖️ xCode Journal
Канадский политик во время выступления случайно зачитал ответ чат-бота, оставленный в тексте:
«Вот более естественная, плавная версия этого фрагмента, которая звучит как парламентская речь…»
✖️ xCode Journal

Пост от 28.07.2026 14:17
50
0
0
🤣 Промптил тренер. А это продакт, который присвоил все заслуги себе)
✖️ xCode Journal
✖️ xCode Journal

Пост от 27.07.2026 22:27
66
0
2
😎 Anthropic выпустила официальный гайд по работе с новенькой Claude Opus 5
Главный совет — перестаньте микроменеджить модель. Opus 5 лучше работает, если просто дать ей полное ТЗ и не просить лишний раз перепроверять себя.
Ещё один нюанс: если хотите короткие ответы, теперь это нужно писать явно, так как по умолчанию модель стала гораздо многословнее.
✖️ xCode Journal
Главный совет — перестаньте микроменеджить модель. Opus 5 лучше работает, если просто дать ей полное ТЗ и не просить лишний раз перепроверять себя.
Ещё один нюанс: если хотите короткие ответы, теперь это нужно писать явно, так как по умолчанию модель стала гораздо многословнее.
✖️ xCode Journal
Пост от 26.07.2026 09:43
27
0
2
Attack Replay: открытая тулза для тестов СЗИ
Хочешь быть уверен, что твоя защита реально рубит угрозы? Тогда перед внедрением проводишь приемочные испытания. Но готовить такие тесты — тот еще геморрой: под каждый продукт надо адаптировать трафик и сценарии.
Нормальной открытой утилиты, которая бы тупо брала трафик, модила его и воспроизводила, толком нет. Коммерческие решения стоят дорого или не покрывают всех ништяков. А спецам приходится дергать разные проги, теряя время на переключения.
Мы забацали Attack Replay — это опенсорсная утилита, которая сваливает в кучу функции нескольких инструментов и автоматом готовит и запускает тесты. В статье расписано, зачем это нужно, как устроено и какие результаты, а еще там ссылка на GitHub с кодом и готовыми pcap-файлами. Читать далее
👉 QA-логия
Хочешь быть уверен, что твоя защита реально рубит угрозы? Тогда перед внедрением проводишь приемочные испытания. Но готовить такие тесты — тот еще геморрой: под каждый продукт надо адаптировать трафик и сценарии.
Нормальной открытой утилиты, которая бы тупо брала трафик, модила его и воспроизводила, толком нет. Коммерческие решения стоят дорого или не покрывают всех ништяков. А спецам приходится дергать разные проги, теряя время на переключения.
Мы забацали Attack Replay — это опенсорсная утилита, которая сваливает в кучу функции нескольких инструментов и автоматом готовит и запускает тесты. В статье расписано, зачем это нужно, как устроено и какие результаты, а еще там ссылка на GitHub с кодом и готовыми pcap-файлами. Читать далее
👉 QA-логия

Пост от 26.07.2026 09:43
23
0
1
Ребята из Т‑Банка, которые шарят за кредитные продукты для физлиц, рассказали, как они гоняли нагрузочные тесты на Zeebe — движке, на котором базируется Camunda 8. Всё это замутили, когда искали, чем бы заменить Camunda 7.
Про Zeebe ходит куча мифов: мол, тормозит, настраивать — геморрой, да и в целом нестабильная штука. Авторы справедливо замечают, что большинство таких отзывов базируется на информации про очень старые версии.
Команда решила не верить слухам, а проверить всё сама, учитывая, что продукт уже успел апгрейднуться. Детали выкатили в статье на Хабре.
Почитать
👉 QA-логия
Про Zeebe ходит куча мифов: мол, тормозит, настраивать — геморрой, да и в целом нестабильная штука. Авторы справедливо замечают, что большинство таких отзывов базируется на информации про очень старые версии.
Команда решила не верить слухам, а проверить всё сама, учитывая, что продукт уже успел апгрейднуться. Детали выкатили в статье на Хабре.
Почитать
👉 QA-логия

Пост от 26.07.2026 09:43
18
0
2
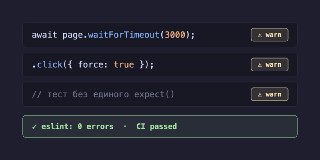
ESLint-plugin-playwright пропускает потенциально опасные тесты
Сценарий простой: тест долбит клик с force: true, потом тупит waitForTimeout(3000) и забывает хоть что-то проверить. Но CI с воткнутым eslint-plugin-playwright радостно зелёный — все три этих говнокейса в recommended-настройках висят как warning.
Автор разобрал исходники плагина и выяснил, что там объявлено error, а что просто warn. Внутри лежит конфиг, который разруливает этот бардак. Плюс список из десяти правил ревью, которые линтер никогда сам не отловит.
Читать далее: habr.com/ru/articles/1058692
👉 QA-логия
Сценарий простой: тест долбит клик с force: true, потом тупит waitForTimeout(3000) и забывает хоть что-то проверить. Но CI с воткнутым eslint-plugin-playwright радостно зелёный — все три этих говнокейса в recommended-настройках висят как warning.
Автор разобрал исходники плагина и выяснил, что там объявлено error, а что просто warn. Внутри лежит конфиг, который разруливает этот бардак. Плюс список из десяти правил ревью, которые линтер никогда сам не отловит.
Читать далее: habr.com/ru/articles/1058692
👉 QA-логия