Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «Гайды программиста»

Гайды программиста
6.2K
0
908
12
0
Ссылка: @Portal_v_IT
Сотрудничество, авторские права: @oleginc, @tatiana_inc
Менеджер: @Spiral_Yuri
Канал на бирже: https://telega.in/c/it_guides
РКН: clck.ru/3Jao8n
Сотрудничество, авторские права: @oleginc, @tatiana_inc
Менеджер: @Spiral_Yuri
Канал на бирже: https://telega.in/c/it_guides
РКН: clck.ru/3Jao8n
Подписчики
Всего
15 364
Сегодня
0
Просмотров на пост
Всего
336
ER
Общий
1.88%
Суточный
1.5%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 6 178 постов
Смотреть все посты
Пост от 03.08.2026 17:07
1
0
0
КИТАЙ vs ЗАПАД: Kimi K3 vs Claude
16 июля вышла новая китайская модель Kimi K3. Она абсолютно бесплатная, держит 1 000 000 токенов контекста и работает на уровне топовых закрытых моделей.
Помните как я тестировал Claude для своих подписок? Тоже самое решил сделать через Kimi.
В Telegram через настройки выгрузил архив своих подписок и загрузил файл в нейросеть. Модель выбрала каналы, которые чаще всего пересекались в «похожих», и на их основе собрала базу.
Около недели читал найденные ресурсы — авторы действительно интересные, без глупого копипаста. Каждый канал в подборке получился уникальным и экспертным. Подписывайтесь, каждый найдет для себя что-то полезное
• ИИ: фишки нейрогенерации, библиотеки промптов и вайб-кодинг.
• Автоматизация: как внедрять нейросети в бизнес-процессы и экономить время.
• IT и карьера: как развивать свои проекты, расти в грейде и выходить на топовые офферы.
Сохраняйте подборку себе или попробуйте выгрузить свои данные и прогнать их через Kimi K3
Подписка в 1 клик:
👉 telemetr.me/addlist/7ZtK-j24E6ljNmQy
16 июля вышла новая китайская модель Kimi K3. Она абсолютно бесплатная, держит 1 000 000 токенов контекста и работает на уровне топовых закрытых моделей.
Помните как я тестировал Claude для своих подписок? Тоже самое решил сделать через Kimi.
В Telegram через настройки выгрузил архив своих подписок и загрузил файл в нейросеть. Модель выбрала каналы, которые чаще всего пересекались в «похожих», и на их основе собрала базу.
Около недели читал найденные ресурсы — авторы действительно интересные, без глупого копипаста. Каждый канал в подборке получился уникальным и экспертным. Подписывайтесь, каждый найдет для себя что-то полезное
• ИИ: фишки нейрогенерации, библиотеки промптов и вайб-кодинг.
• Автоматизация: как внедрять нейросети в бизнес-процессы и экономить время.
• IT и карьера: как развивать свои проекты, расти в грейде и выходить на топовые офферы.
Сохраняйте подборку себе или попробуйте выгрузить свои данные и прогнать их через Kimi K3
Подписка в 1 клик:
👉 telemetr.me/addlist/7ZtK-j24E6ljNmQy

Пост от 03.08.2026 11:07
106
0
1
Chart.js 📊 – простая и гибкая JavaScript-библиотека для создания красивых, responsive графиков с анимациями и интерактивностью.
Аналогия: Если Excel графики – чёрно-белые схемы из учебника, то Chart.js – интерактивная инфографика из современных презентаций с анимациями и hover-эффектами!
🎨 Ключевые особенности:
- 8 типов графиков – линейные, столбчатые, круговые, радарные и другие
- Responsive – адаптируются под размер экрана автоматически
- Анимации – плавное появление данных при загрузке
- Canvas-based – производительный рендеринг через HTML5
📈 Кто использует:
GitLab, SpaceX, BBC используют Chart.js для дашбордов. Более 6 млн загрузок в неделю. Самая популярная библиотека графиков.
📊 Итог: Chart.js = данные в красивых графиках! Просто, быстро, красиво! 🚀✨
#Term | Гайды Программиста
Аналогия: Если Excel графики – чёрно-белые схемы из учебника, то Chart.js – интерактивная инфографика из современных презентаций с анимациями и hover-эффектами!
🎨 Ключевые особенности:
- 8 типов графиков – линейные, столбчатые, круговые, радарные и другие
- Responsive – адаптируются под размер экрана автоматически
- Анимации – плавное появление данных при загрузке
- Canvas-based – производительный рендеринг через HTML5
📈 Кто использует:
GitLab, SpaceX, BBC используют Chart.js для дашбордов. Более 6 млн загрузок в неделю. Самая популярная библиотека графиков.
📊 Итог: Chart.js = данные в красивых графиках! Просто, быстро, красиво! 🚀✨
#Term | Гайды Программиста
Пост от 02.08.2026 19:07
87
0
2
Sharp 🖼 – высокопроизводительная библиотека для обработки изображений в Node.js, использующая libvips для молниеносной работы с JPEG, PNG, WebP.
Аналогия: Если ImageMagick – фотолаборатория с ручной проявкой, то Sharp – автоматическая линия обработки фото на заводе Canon. Быстро, качественно, масштабируемо!
⚡️ Ключевые особенности:
- В 4-5 раз быстрее ImageMagick и GraphicsMagick
- Resize, crop, rotate – все базовые операции оптимизированы
- Форматы – конвертация между JPEG, PNG, WebP, AVIF, TIFF
- Metadata – чтение и модификация EXIF данных
🎨 Кто использует:
BBC, Shopify, loveholidays используют Sharp для обработки миллионов изображений. Более 7 млн загрузок в неделю. Must-have для работы с изображениями.
🖼 Итог: Sharp = обработка изображений на скорости! Resize в миллисекундах! ⚡️✨
#Term | Гайды Программиста
Аналогия: Если ImageMagick – фотолаборатория с ручной проявкой, то Sharp – автоматическая линия обработки фото на заводе Canon. Быстро, качественно, масштабируемо!
⚡️ Ключевые особенности:
- В 4-5 раз быстрее ImageMagick и GraphicsMagick
- Resize, crop, rotate – все базовые операции оптимизированы
- Форматы – конвертация между JPEG, PNG, WebP, AVIF, TIFF
- Metadata – чтение и модификация EXIF данных
🎨 Кто использует:
BBC, Shopify, loveholidays используют Sharp для обработки миллионов изображений. Более 7 млн загрузок в неделю. Must-have для работы с изображениями.
🖼 Итог: Sharp = обработка изображений на скорости! Resize в миллисекундах! ⚡️✨
#Term | Гайды Программиста
Пост от 02.08.2026 11:07
62
0
1
Winston 📝 – универсальная библиотека логирования для Node.js с поддержкой множественных транспортов, уровней и форматов логов.
Аналogия: Если console.log – записка на холодильнике, то Winston – профессиональная система видеонаблюдения с записью на диск, отправкой в облако и разными уровнями важности!
🔍 Ключевые особенности:
- Множественные транспорты – файлы, консоль, база данных, external сервисы
- Log levels – error, warn, info, debug для фильтрации
- Форматирование – JSON, простой текст, цветной вывод
- Профилирование – замер времени выполнения операций
💼 Кто использует:
IBM, Oracle, NASA используют Winston для enterprise логирования. Более 8 млн загрузок в неделю. Стандарт для Node.js logging.
📝 Революция: Winston = профессиональное логирование! От development до production! 🚀💙
#Term | Гайды Программиста
Аналogия: Если console.log – записка на холодильнике, то Winston – профессиональная система видеонаблюдения с записью на диск, отправкой в облако и разными уровнями важности!
🔍 Ключевые особенности:
- Множественные транспорты – файлы, консоль, база данных, external сервисы
- Log levels – error, warn, info, debug для фильтрации
- Форматирование – JSON, простой текст, цветной вывод
- Профилирование – замер времени выполнения операций
💼 Кто использует:
IBM, Oracle, NASA используют Winston для enterprise логирования. Более 8 млн загрузок в неделю. Стандарт для Node.js logging.
📝 Революция: Winston = профессиональное логирование! От development до production! 🚀💙
#Term | Гайды Программиста
Пост от 01.08.2026 19:07
57
0
1
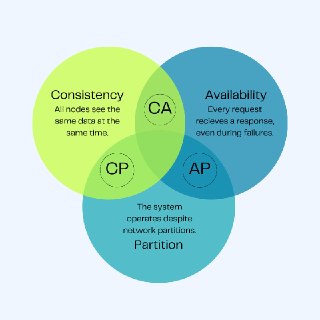
CAP Theorem (Теорема CAP) 🔺
Определение: Фундаментальное правило распределенных баз данных, гласящее, что система может одновременно обеспечить только два из трех свойств: Согласованность (C), Доступность (A) и Устойчивость к разделению сети (P).
Аналогия: Классический выбор при ремонте: "Быстро, Качественно, Дешево — выберите любые два". Быстро и дешево будет некачественно, а качественно и быстро — очень дорого.
Особенности: Так как обрывы связи (P) в интернете неизбежны, инженерам всегда приходится выбирать: либо база отдаст устаревшие данные, но продолжит работать (AP), либо заблокируется до починки сети ради идеальной точности (CP).
Итог: Теорема CAP — это суровый закон компромиссов. Идеальной базы данных не существует, физика всегда заставит вас чем-то пожертвовать! ✨
#Term | Гайды Программиста
Определение: Фундаментальное правило распределенных баз данных, гласящее, что система может одновременно обеспечить только два из трех свойств: Согласованность (C), Доступность (A) и Устойчивость к разделению сети (P).
Аналогия: Классический выбор при ремонте: "Быстро, Качественно, Дешево — выберите любые два". Быстро и дешево будет некачественно, а качественно и быстро — очень дорого.
Особенности: Так как обрывы связи (P) в интернете неизбежны, инженерам всегда приходится выбирать: либо база отдаст устаревшие данные, но продолжит работать (AP), либо заблокируется до починки сети ради идеальной точности (CP).
Итог: Теорема CAP — это суровый закон компромиссов. Идеальной базы данных не существует, физика всегда заставит вас чем-то пожертвовать! ✨
#Term | Гайды Программиста
Пост от 01.08.2026 12:07
52
0
0
📣Стол компьютерный с подъемным механизмом
Цена: ~15000₽
Рейтинг: 4.8😀
Отзывов: 1.431 💬
🖱 Заказать
Компьютерный стол с электрической регулировкой высоты позволит работать сидя или стоя одним нажатием кнопки. Просторная столешница 150×78 см легко вместит несколько мониторов, ноутбук и всю периферию. Отличный выбор для программистов и удаленщиков, которые проводят за компьютером весь день и хотят сделать рабочее место более комфортным и эргономичным.
#стол #регулировка
Находки Программиста
Цена: ~15000₽
Рейтинг: 4.8😀
Отзывов: 1.431 💬
🖱 Заказать
Компьютерный стол с электрической регулировкой высоты позволит работать сидя или стоя одним нажатием кнопки. Просторная столешница 150×78 см легко вместит несколько мониторов, ноутбук и всю периферию. Отличный выбор для программистов и удаленщиков, которые проводят за компьютером весь день и хотят сделать рабочее место более комфортным и эргономичным.
#стол #регулировка
Находки Программиста

Пост от 01.08.2026 11:07
35
0
2
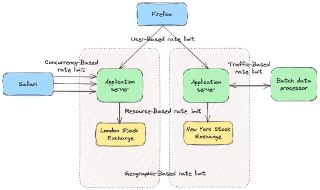
Rate Limiting (Ограничение частоты запросов) 🚦
Определение: Механизм контроля сетевого трафика, искусственно ограничивающий количество запросов от одного IP-адреса или пользователя за определенный промежуток времени.
Аналогия: Турникет в метро. Даже если огромная толпа попытается пройти одновременно, створки будут пропускать строго по одному человеку, чтобы на станции не началась давка и коллапс.
Особенности: Защищает систему от перегрузки, DDoS-атак и попыток подбора паролей. Если лимит исчерпан, сервер перестает думать и просто отдает ошибку 429 (Too Many Requests).
Итог: Rate Limiting — это строгий вышибала на входе. Не позволяет одному наглому клиенту монополизировать все ресурсы сервера! ✨
#Term | Гайды Программиста
Определение: Механизм контроля сетевого трафика, искусственно ограничивающий количество запросов от одного IP-адреса или пользователя за определенный промежуток времени.
Аналогия: Турникет в метро. Даже если огромная толпа попытается пройти одновременно, створки будут пропускать строго по одному человеку, чтобы на станции не началась давка и коллапс.
Особенности: Защищает систему от перегрузки, DDoS-атак и попыток подбора паролей. Если лимит исчерпан, сервер перестает думать и просто отдает ошибку 429 (Too Many Requests).
Итог: Rate Limiting — это строгий вышибала на входе. Не позволяет одному наглому клиенту монополизировать все ресурсы сервера! ✨
#Term | Гайды Программиста