Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «Highload — медіа для розробників»

Highload — медіа для розробників
9.6K
6.7K
234
102
35.6K
Розповідаємо про людей, які створюють код, та про код, який вони пишуть.
Зв'язатися із редакцією можна тут: news@highload.today. А щодо розміщення реклами, будь ласка, пишіть на specials@highload.today.
Наш чат telemetr.me/highloadchatt
Зв'язатися із редакцією можна тут: news@highload.today. А щодо розміщення реклами, будь ласка, пишіть на specials@highload.today.
Наш чат telemetr.me/highloadchatt
Подписчики
Всего
4 130
Сегодня
0
Просмотров на пост
Всего
920
ER
Общий
21.22%
Суточный
19%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 9 602 постов
Смотреть все посты
Пост от 31.07.2026 17:28
332
0
5
Новий тренд: як компанії з однієї людини заробляють мільйони
Розвиток нейромереж усунув потребу у великому штаті для побудови масштабного бізнесу. У світі стрімко зростає клас підприємців, які самотужки будують компанії з мільйонними оборотами, а штучний інтелект бере на себе весь спектр рутинних задач — від написання й налагодження коду до техпідтримки, маркетингу, бухгалтерії та обробки повернень.
Масштаб зсуву підтверджує аналіз платіжної системи Stripe: кількість фаундерів-одинаків на платформі з виручкою понад $1 млн подвоїлася між 2023 та 2025 роками, а число тих, хто перетнув позначку $10 млн, за цей же час зросло майже втричі.
Головний економіст Stripe Ерні Тедескі зазначає, що раніше люди без ділових зв’язків чи особливої кмітливості часто не знали, як зрушити свою ідею з місця — тепер штучний інтелект здатен виконувати роль консультанта та бізнес-партнера. Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google
Розвиток нейромереж усунув потребу у великому штаті для побудови масштабного бізнесу. У світі стрімко зростає клас підприємців, які самотужки будують компанії з мільйонними оборотами, а штучний інтелект бере на себе весь спектр рутинних задач — від написання й налагодження коду до техпідтримки, маркетингу, бухгалтерії та обробки повернень.
Масштаб зсуву підтверджує аналіз платіжної системи Stripe: кількість фаундерів-одинаків на платформі з виручкою понад $1 млн подвоїлася між 2023 та 2025 роками, а число тих, хто перетнув позначку $10 млн, за цей же час зросло майже втричі.
Головний економіст Stripe Ерні Тедескі зазначає, що раніше люди без ділових зв’язків чи особливої кмітливості часто не знали, як зрушити свою ідею з місця — тепер штучний інтелект здатен виконувати роль консультанта та бізнес-партнера. Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google

😁
3
👍
1
👎
1
Пост от 31.07.2026 16:19
218
0
5
Агент Gemini Spark став доступний для користувачів в Україні
Компанія Google випустила одразу два великих оновлення для свого персонального ШІ-агента Gemini Spark: інтеграцію з браузером Chrome на комп’ютері та розширення доступу до сервісу для передплатників базового тарифного плану AI Pro (близько $20 на місяць) в понад 160 нових країнах, включно з Україною.
До цього Spark був доступний виключно власникам значно дорожчого тарифу AI Ultra ($100–200 на місяць).
Що стосується оновлення, то раніше Gemini Spark мав доступ лише до віддаленого веб-браузера. Тепер персональний ШІ-агент Google для автоматизації повсякденних задач може використовувати десктопний Chrome на пристрої користувача — з авторизованими обліковими записами та збереженими паролями. Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google
Компанія Google випустила одразу два великих оновлення для свого персонального ШІ-агента Gemini Spark: інтеграцію з браузером Chrome на комп’ютері та розширення доступу до сервісу для передплатників базового тарифного плану AI Pro (близько $20 на місяць) в понад 160 нових країнах, включно з Україною.
До цього Spark був доступний виключно власникам значно дорожчого тарифу AI Ultra ($100–200 на місяць).
Що стосується оновлення, то раніше Gemini Spark мав доступ лише до віддаленого веб-браузера. Тепер персональний ШІ-агент Google для автоматизації повсякденних задач може використовувати десктопний Chrome на пристрої користувача — з авторизованими обліковими записами та збереженими паролями. Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google

🔥
3
Пост от 31.07.2026 15:28
386
0
8
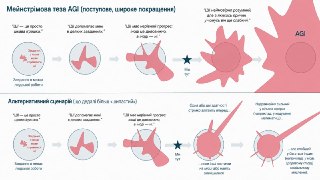
«Даних недостатньо»: екс-дослідник OpenAI прогнозує, що ШІ-компаніям доведеться вкласти ще $100 млрд
Колишній співробітник OpenAI Ендрю Хо переконаний, що великі мовні моделі погано узагальнюють знання — навіть у такому напрямку, як програмування, їхня продуктивність залишається нестабільною. На його думку, корінь проблеми — брак якісних тренувальних даних.
Щоб підвищити продуктивність наступного покоління LLM, одного масштабування буде недостатньо. Хо очікує, що ШІ-лабораторії у найближчі роки витратять понад $100 млрд на додатковий збір даних.
Він також скептично ставиться до надвисоких оцінок вартості провідних лабораторій на кшталт OpenAI чи Anthropic: вони хронічно збиткові, бо змушені вкладати дедалі більші суми в нові моделі лише для того, щоб випереджати дешевших конкурентів на кшталт Qwen чи Kimi. Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google
Колишній співробітник OpenAI Ендрю Хо переконаний, що великі мовні моделі погано узагальнюють знання — навіть у такому напрямку, як програмування, їхня продуктивність залишається нестабільною. На його думку, корінь проблеми — брак якісних тренувальних даних.
Щоб підвищити продуктивність наступного покоління LLM, одного масштабування буде недостатньо. Хо очікує, що ШІ-лабораторії у найближчі роки витратять понад $100 млрд на додатковий збір даних.
Він також скептично ставиться до надвисоких оцінок вартості провідних лабораторій на кшталт OpenAI чи Anthropic: вони хронічно збиткові, бо змушені вкладати дедалі більші суми в нові моделі лише для того, щоб випереджати дешевших конкурентів на кшталт Qwen чи Kimi. Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google
😁
5
🤔
2
Пост от 31.07.2026 14:31
490
0
8
Крипта під ударом: з гаманців Coldcard за 25 хвилин вивели 594 BTC
Із приблизно 500 апаратних холодних гаманців Coldcard приблизно за 25 хвилин зникло 594 BTC ($38 млн) — причиною стала вразливість у прошивці, через яку пристрій замість справжньої апаратної генерації випадкових чисел використовував передбачувані дані.
Хронологія інциденту. Сьогодні вночі, в п’ятницю, між 01:31 та 01:56 UTC, зловмисник вивів кошти приблизно з 500 окремих гаманців Coldcard — апаратного гаманця канадської компанії Coinkite. Крадіжка пройшла у 500 транзакціях у межах трьох блоків: згодом 562 BTC консолідували на одній адресі, яка відтоді не рухалася.
Усі постраждалі гаманці були одноключовими (single-signature) і містили понад 0,15 BTC кожен; частина з них не використовувалася роками, а вік монет — від 2021-го до 2026 року — майже точно збігається з... Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google
Із приблизно 500 апаратних холодних гаманців Coldcard приблизно за 25 хвилин зникло 594 BTC ($38 млн) — причиною стала вразливість у прошивці, через яку пристрій замість справжньої апаратної генерації випадкових чисел використовував передбачувані дані.
Хронологія інциденту. Сьогодні вночі, в п’ятницю, між 01:31 та 01:56 UTC, зловмисник вивів кошти приблизно з 500 окремих гаманців Coldcard — апаратного гаманця канадської компанії Coinkite. Крадіжка пройшла у 500 транзакціях у межах трьох блоків: згодом 562 BTC консолідували на одній адресі, яка відтоді не рухалася.
Усі постраждалі гаманці були одноключовими (single-signature) і містили понад 0,15 BTC кожен; частина з них не використовувалася роками, а вік монет — від 2021-го до 2026 року — майже точно збігається з... Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google

😱
3
🤯
2
Пост от 31.07.2026 11:45
573
3
3
Android запускає автоматичний бекап документів на Google Диск
Компанія Google запустила на Android нову функцію резервного копіювання документів — тепер файли, завантажені на смартфон чи планшет, автоматично зберігаються в Google Диск.
Функція локального бекапу дозволяє автоматично вивантажувати в Google Drive файли, збережені на пристрої, — наприклад, завантаження з мобільного браузера Chrome. Це зручно на випадок втрати телефону, однак варто пам’ятати: такі файли враховуються у загальний ліміт сховища Google-акаунта.
У розділі «Мій диск» з’явиться нова папка Android backups, а всередині неї — ще одна, названа на честь... Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google
Компанія Google запустила на Android нову функцію резервного копіювання документів — тепер файли, завантажені на смартфон чи планшет, автоматично зберігаються в Google Диск.
Функція локального бекапу дозволяє автоматично вивантажувати в Google Drive файли, збережені на пристрої, — наприклад, завантаження з мобільного браузера Chrome. Це зручно на випадок втрати телефону, однак варто пам’ятати: такі файли враховуються у загальний ліміт сховища Google-акаунта.
У розділі «Мій диск» з’явиться нова папка Android backups, а всередині неї — ще одна, названа на честь... Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google

👍
3
🤣
1
Пост от 31.07.2026 10:01
207
0
5
OpenAI радикально знизила ціни на GPT-5.6 — але не для всіх версій
OpenAI знизила ціни на GPT-5.6 Luna та Terra, залишивши без змін вартість флагманської Sol — компанія пояснює це підвищенням ефективності інфраструктури, яка обслуговує моделі.
Оголошення про зниження цін на дві версії GPT-5.6 сталося лише через три тижні після запуску моделі, тоді як зазвичай цінові корективи компанії з’являються через кілька місяців після релізу.
GPT-5.6 Luna — найшвидша та найдешевша версія моделі — подешевшає приблизно на 80%. Нова ціна становитиме... Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google
OpenAI знизила ціни на GPT-5.6 Luna та Terra, залишивши без змін вартість флагманської Sol — компанія пояснює це підвищенням ефективності інфраструктури, яка обслуговує моделі.
Оголошення про зниження цін на дві версії GPT-5.6 сталося лише через три тижні після запуску моделі, тоді як зазвичай цінові корективи компанії з’являються через кілька місяців після релізу.
GPT-5.6 Luna — найшвидша та найдешевша версія моделі — подешевшає приблизно на 80%. Нова ціна становитиме... Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google

👍
2
Пост от 31.07.2026 09:01
352
0
2
Хто такі «польові інженери» і чому вони стали найбільш затребуваними IT-фахівцями
Поки одні технологічні спеціальності страждають від скорочень, попит на «польових інженерів» (forward-deployed engineers, FDE) злітає шаленими темпами — і зараз ця роль претендує на статус найзатребуванішої спеціальності в ІТ-індустрії.
Рекрутингова компанія Christian & Timbers (C&T) підрахувала: у США налічується лише близько 2000 інженерів, які поєднують галузеву експертизу, авторитет і практичний досвід впровадження штучного інтелекту настільки, щоб гарантовано приносити компаніям окупність інвестицій. «Не 2000 доступних, — йдеться у звіті, наданому виданню TechCrunch на ексклюзивних умовах, — 2000 загалом».
FDE — це інженери, які працюють безпосередньо всередині клієнтських організацій, допомагаючи будувати, впроваджувати й розгортати софт або моделі штучного інтелекту. За оцінками C&T, попит на таких спеціалістів до кінця року... Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google
Поки одні технологічні спеціальності страждають від скорочень, попит на «польових інженерів» (forward-deployed engineers, FDE) злітає шаленими темпами — і зараз ця роль претендує на статус найзатребуванішої спеціальності в ІТ-індустрії.
Рекрутингова компанія Christian & Timbers (C&T) підрахувала: у США налічується лише близько 2000 інженерів, які поєднують галузеву експертизу, авторитет і практичний досвід впровадження штучного інтелекту настільки, щоб гарантовано приносити компаніям окупність інвестицій. «Не 2000 доступних, — йдеться у звіті, наданому виданню TechCrunch на ексклюзивних умовах, — 2000 загалом».
FDE — це інженери, які працюють безпосередньо всередині клієнтських організацій, допомагаючи будувати, впроваджувати й розгортати софт або моделі штучного інтелекту. За оцінками C&T, попит на таких спеціалістів до кінця року... Читати далі на Highload 👉
Facebook | LinkedIn | Додати в Google

👍
2
🤔
2