Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «ForgetMe | Нейросети»

ForgetMe | Нейросети
4.8K
30.9K
15
6
42.9K
Добро пожаловать в мир нейросетей и высоких технологий
Купить подписку на ChatGPT/Claude/Gemini - @forgetshop_bot
Админ - @forgetmeadm
Купить рекламу на бирже: https://telega.in/c/forgetmeai
Купить подписку на ChatGPT/Claude/Gemini - @forgetshop_bot
Админ - @forgetmeadm
Купить рекламу на бирже: https://telega.in/c/forgetmeai
Подписчики
Всего
13 908
Сегодня
+30
Просмотров на пост
Всего
2 224
ER
Общий
15.9%
Суточный
10.5%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 4 784 постов
Смотреть все посты
Пост от 06.06.2026 23:03
509
11
24
🔥 БЕСПЛАТНО ПОДКЛЮЧАЕМ API DEEPSEEK V4 К HERMES AGENT
Сделал FreeDeepseekAPI — локальный прокси, который позволяет использовать DeepSeek Web Chat почти как обычный OpenAI API.
То есть можно подключить DeepSeek к:
— Hermes/OpenClaw;
— своим Python/JS-скриптам;
— OpenAI SDK;
— локальным агентам;
— любым тулзам, где есть OpenAI-compatible endpoint.
В видео показываю установку, авторизацию, запуск сервера и реальные запросы через локальный API.
✴️ Видео — https://youtu.be/m9Lj3UCCRcI
📌 Ссылки из видео:
1. GitHub — https://github.com/ForgetMeAI/FreeDeepseekAPI
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #гайд
Сделал FreeDeepseekAPI — локальный прокси, который позволяет использовать DeepSeek Web Chat почти как обычный OpenAI API.
То есть можно подключить DeepSeek к:
— Hermes/OpenClaw;
— своим Python/JS-скриптам;
— OpenAI SDK;
— локальным агентам;
— любым тулзам, где есть OpenAI-compatible endpoint.
В видео показываю установку, авторизацию, запуск сервера и реальные запросы через локальный API.
✴️ Видео — https://youtu.be/m9Lj3UCCRcI
📌 Ссылки из видео:
1. GitHub — https://github.com/ForgetMeAI/FreeDeepseekAPI
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #гайд

👍
10
🔥
7
❤
2
👏
1
Пост от 06.06.2026 15:51
1 067
4
62
⚡️ Нашёл приватную альтернативу NotebookLM, которую можно запустить локально
Называется Open Notebook — open-source проект, который пытается повторить идею NotebookLM, но без привязки к Google.
Можно загружать свои источники, задавать вопросы по документам, делать заметки, искать по базе и даже генерировать подкасты по материалам.
Что умеет:
🟡 работает с PDF, Word, PowerPoint, Excel, EPUB, Markdown, HTML;
🟡 понимает аудио, видео, YouTube-ссылки, веб-страницы и RSS;
🟡 даёт чат по вашим источникам и заметкам;
🟡 есть full-text + vector search;
🟡 можно делать подкасты не только в формате «2 ведущих», а настраивать 1–4 спикеров;
🟡 поддерживает 18+ AI-провайдеров: OpenAI, Anthropic, Google, Groq, OpenRouter, Ollama, LM Studio и другие;
🟡 ставится через Docker, есть MIT-лицензия и около 26k звёзд на GitHub.
Но важный нюанс: приватность зависит от модели.
Если подключить OpenAI/Claude/Gemini — ваши данные всё равно уходят к облачному провайдеру.
Если хотите прям локально и приватно — надо использовать Ollama или LM Studio с локальной моделью.
Минусы тоже есть: нужно ставить Docker, разбираться с моделями/API-ключами, и цитаты у Open Notebook пока заявлены как более базовые, чем у NotebookLM.
Ссылка: https://github.com/lfnovo/open-notebook
Сайт: https://www.open-notebook.ai/
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #полезности
Называется Open Notebook — open-source проект, который пытается повторить идею NotebookLM, но без привязки к Google.
Можно загружать свои источники, задавать вопросы по документам, делать заметки, искать по базе и даже генерировать подкасты по материалам.
Что умеет:
🟡 работает с PDF, Word, PowerPoint, Excel, EPUB, Markdown, HTML;
🟡 понимает аудио, видео, YouTube-ссылки, веб-страницы и RSS;
🟡 даёт чат по вашим источникам и заметкам;
🟡 есть full-text + vector search;
🟡 можно делать подкасты не только в формате «2 ведущих», а настраивать 1–4 спикеров;
🟡 поддерживает 18+ AI-провайдеров: OpenAI, Anthropic, Google, Groq, OpenRouter, Ollama, LM Studio и другие;
🟡 ставится через Docker, есть MIT-лицензия и около 26k звёзд на GitHub.
Но важный нюанс: приватность зависит от модели.
Если подключить OpenAI/Claude/Gemini — ваши данные всё равно уходят к облачному провайдеру.
Если хотите прям локально и приватно — надо использовать Ollama или LM Studio с локальной моделью.
Минусы тоже есть: нужно ставить Docker, разбираться с моделями/API-ключами, и цитаты у Open Notebook пока заявлены как более базовые, чем у NotebookLM.
Ссылка: https://github.com/lfnovo/open-notebook
Сайт: https://www.open-notebook.ai/
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #полезности
👍
13
❤
4
🔥
3
Пост от 06.06.2026 14:26
1 259
1
25
✴️ Google выкатила Gemma 4 QAT — локальные модели стали заметно легче
Если коротко: это новые официальные версии Gemma 4, которые заранее обучали с учётом 4-битного сжатия.
Обычно модель сначала обучают, а потом «ужимают» — и на этом часто теряется качество.
QAT работает умнее: модель во время обучения уже адаптируется к будущему сжатию, поэтому в 4-битном виде она должна меньше деградировать.
Что важно:
🟡 появились QAT-чекпоинты для Gemma 4 E2B, E4B, 12B, 26B A4B и 31B;
🟡 есть GGUF для llama.cpp / LM Studio / Ollama;
🟡 есть compressed tensors для vLLM / SGLang;
🟡 для мобильных E2B и E4B Google сделала отдельный mobile-формат;
🟡 Gemma 4 E2B в text-only mobile-варианте требует меньше 1 ГБ памяти;
🟡 Gemma 4 12B в Q4_0 по официальной таблице — около 6.7 ГБ только на загрузку весов.
Но нюанс: это не значит «теперь любая большая Gemma летает на любом ноутбуке».
Контекст, KV-cache, софт и конкретный рантайм всё равно съедают память. Особенно если хотите длинные диалоги или агентные сценарии.
Ссылки:
Google Blog — https://blog.google/innovation-and-ai/technology/developers-tools/quantization-aware-training-gemma-4/
Документация Gemma 4 — https://ai.google.dev/gemma/docs/core
Hugging Face QAT — https://huggingface.co/collections/google/gemma-4-qat-q4-0
Mobile QAT — https://huggingface.co/collections/google/gemma-4-qat-mobile
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #новости #gemini
Если коротко: это новые официальные версии Gemma 4, которые заранее обучали с учётом 4-битного сжатия.
Обычно модель сначала обучают, а потом «ужимают» — и на этом часто теряется качество.
QAT работает умнее: модель во время обучения уже адаптируется к будущему сжатию, поэтому в 4-битном виде она должна меньше деградировать.
Что важно:
🟡 появились QAT-чекпоинты для Gemma 4 E2B, E4B, 12B, 26B A4B и 31B;
🟡 есть GGUF для llama.cpp / LM Studio / Ollama;
🟡 есть compressed tensors для vLLM / SGLang;
🟡 для мобильных E2B и E4B Google сделала отдельный mobile-формат;
🟡 Gemma 4 E2B в text-only mobile-варианте требует меньше 1 ГБ памяти;
🟡 Gemma 4 12B в Q4_0 по официальной таблице — около 6.7 ГБ только на загрузку весов.
Но нюанс: это не значит «теперь любая большая Gemma летает на любом ноутбуке».
Контекст, KV-cache, софт и конкретный рантайм всё равно съедают память. Особенно если хотите длинные диалоги или агентные сценарии.
Ссылки:
Google Blog — https://blog.google/innovation-and-ai/technology/developers-tools/quantization-aware-training-gemma-4/
Документация Gemma 4 — https://ai.google.dev/gemma/docs/core
Hugging Face QAT — https://huggingface.co/collections/google/gemma-4-qat-q4-0
Mobile QAT — https://huggingface.co/collections/google/gemma-4-qat-mobile
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #новости #gemini
Изображение
👍
15
🔥
4
❤
3
Пост от 05.06.2026 21:19
900
32
63
🔥 БЕСПЛАТНО ПОДКЛЮЧАЕМ QWEN 3.7 MAX К HERMES AGENT
В видео:
— запускаем FreeQwenApi локально;
— подключаем аккаунт Qwen Chat;
— подключаем это к Hermes Agent;
✴️ Видео - https://youtu.be/b7WudeCJKHs
📌 Ссылки из видео:
1. Fork FreeQwenAPI
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #гайд
В видео:
— запускаем FreeQwenApi локально;
— подключаем аккаунт Qwen Chat;
— подключаем это к Hermes Agent;
✴️ Видео - https://youtu.be/b7WudeCJKHs
📌 Ссылки из видео:
1. Fork FreeQwenAPI
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #гайд

👍
8
❤
5
🔥
2
Пост от 04.06.2026 19:00
1 118
6
43
📛 Bonsai Image 4B — генерация картинок локально, даже на телефоне
PrismML выкатили Bonsai Image 4B — компактные open-weight модели для генерации изображений, которые пытаются утащить text-to-image из облака на обычные устройства: Mac, NVIDIA GPU и даже iPhone.
Что важно:
🟡 есть 1-bit версия: трансформер всего 0.93 GB, это примерно 8.3× меньше, чем FP16 FLUX.2 Klein 4B;
🟡 есть Ternary версия: 1.21 GB, чуть больше, но лучше по качеству и следованию промпту;
🟡 лицензия Apache-2.0, веса лежат на Hugging Face;
🟡 есть демо-репозиторий, WebGPU demo и Bonsai Studio для iPhone;
🟡 по их бенчмаркам Ternary Bonsai даёт около 95% качества FLUX.2 Klein 4B при сильно меньшем размере.
Ссылки:
Hugging Face: https://huggingface.co/collections/prism-ml/bonsai-image
Анонс: https://prismml.com/news/bonsai-image-4b
GitHub demo: https://github.com/PrismML-Eng/Bonsai-Image-Demo
WebGPU demo: https://huggingface.co/spaces/webml-community/bonsai-image-webgpu
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #новости
PrismML выкатили Bonsai Image 4B — компактные open-weight модели для генерации изображений, которые пытаются утащить text-to-image из облака на обычные устройства: Mac, NVIDIA GPU и даже iPhone.
Что важно:
🟡 есть 1-bit версия: трансформер всего 0.93 GB, это примерно 8.3× меньше, чем FP16 FLUX.2 Klein 4B;
🟡 есть Ternary версия: 1.21 GB, чуть больше, но лучше по качеству и следованию промпту;
🟡 лицензия Apache-2.0, веса лежат на Hugging Face;
🟡 есть демо-репозиторий, WebGPU demo и Bonsai Studio для iPhone;
🟡 по их бенчмаркам Ternary Bonsai даёт около 95% качества FLUX.2 Klein 4B при сильно меньшем размере.
Ссылки:
Hugging Face: https://huggingface.co/collections/prism-ml/bonsai-image
Анонс: https://prismml.com/news/bonsai-image-4b
GitHub demo: https://github.com/PrismML-Eng/Bonsai-Image-Demo
WebGPU demo: https://huggingface.co/spaces/webml-community/bonsai-image-webgpu
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #новости


👍
7
🔥
7
❤
1
Пост от 04.06.2026 16:56
1 202
0
16
⚡️ Совет на 2026 год – изучите вайбкодинг
Привет. Меня зовут Кирилл. Я создаю топовые подборки с уроками по AI и вайбкодингу:
— 37 MCP серверов: дизайн, разработка, Тесты/QA, деплой
— 78 скиллов: парсинг, UI/UX, аналитика, безопасность
— 60+ субагентов: рефакторинг, SEO, CI/CD, документация
— 44 промпта для дебага: поиск ошибок, оптимизация кода
— 130 гайдов по: Claude Code, Antigravity, Cursor, Lovable, ChatGPT
Всего 10 минут в день на канале и ты научишься вайбкодить автоматизации любой сложности.
Материалы в закрепе, постоянно пополняются👆🏻
#реклама
Привет. Меня зовут Кирилл. Я создаю топовые подборки с уроками по AI и вайбкодингу:
— 37 MCP серверов: дизайн, разработка, Тесты/QA, деплой
— 78 скиллов: парсинг, UI/UX, аналитика, безопасность
— 60+ субагентов: рефакторинг, SEO, CI/CD, документация
— 44 промпта для дебага: поиск ошибок, оптимизация кода
— 130 гайдов по: Claude Code, Antigravity, Cursor, Lovable, ChatGPT
Всего 10 минут в день на канале и ты научишься вайбкодить автоматизации любой сложности.
Материалы в закрепе, постоянно пополняются👆🏻
#реклама

👍
3
❤
2
🔥
2
😁
1
Пост от 04.06.2026 11:10
1 147
34
27
⚡️ Ideogram 4.0 вышел с открытыми весами — и это один из самых интересных релизов для генерации картинок
Ideogram выпустили Ideogram 4.0 — свою первую open-weight text-to-image модель.
Главный акцент не просто на “красивых картинках”, а на том, где многие генераторы до сих пор ломаются: текст внутри изображения, постеры, логотипы, рекламные макеты, вывески, композиция и точный контроль дизайна.
Что важно:
🟡 модель на 9.3B параметров;
🟡 генерирует изображения до native 2K;
🟡 умеет лучше работать с типографикой и текстом внутри картинки;
🟡 поддерживает structured JSON prompting — можно точнее описывать стиль, композицию, свет, цвета и объекты;
🟡 есть explicit bounding-box layout control — можно задавать, где именно должны быть элементы;
🟡 веса доступны на Hugging Face, код — на GitHub;
🟡 модель уже работает на сайте Ideogram и через API.
По локальному запуску:
🟡 есть две версии: nf4 и fp8;
🟡 nf4 — CUDA-only, то есть в первую очередь для NVIDIA GPU;
🟡 сами веса nf4 занимают примерно 15 GB, поэтому для нормального локального запуска я бы ориентировался минимум на 24 GB VRAM;
🟡 16 GB VRAM может быть слишком впритык, особенно на высоких разрешениях;
🟡 версия fp8 весит примерно 25–26 GB, так что там уже логичнее смотреть в сторону 32 GB+ VRAM / RAM;
🟡 на Mac / CPU теоретически можно через fp8, но это уже скорее “запустить ради эксперимента”, а не комфортно генерировать.
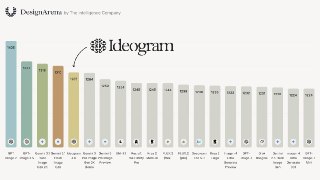
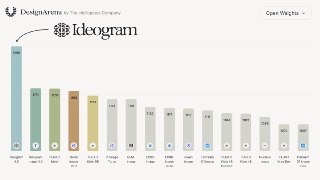
По бенчмаркам Ideogram заявляет, что 4.0 — лучший open-weight image model на дизайне. В Design Arena он уступает только закрытым моделям от гигантов вроде GPT/Gemini, но среди открытых моделей идёт первым.
Важный нюанс: это не совсем “свободная open-source модель без условий”. Веса открыты, но лицензия у моделей — Ideogram 4 Non-Commercial, плюс доступ на Hugging Face gated. То есть для экспериментов, ресерча и локальных тестов — круто, но для коммерческого использования нужно внимательно смотреть условия.
GitHub: https://github.com/ideogram-oss/ideogram4
Модели: https://huggingface.co/collections/ideogram-ai/ideogram-4
Анонс: https://ideogram.ai/news/ideogram-4.0/
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #новости #ideogram
Ideogram выпустили Ideogram 4.0 — свою первую open-weight text-to-image модель.
Главный акцент не просто на “красивых картинках”, а на том, где многие генераторы до сих пор ломаются: текст внутри изображения, постеры, логотипы, рекламные макеты, вывески, композиция и точный контроль дизайна.
Что важно:
🟡 модель на 9.3B параметров;
🟡 генерирует изображения до native 2K;
🟡 умеет лучше работать с типографикой и текстом внутри картинки;
🟡 поддерживает structured JSON prompting — можно точнее описывать стиль, композицию, свет, цвета и объекты;
🟡 есть explicit bounding-box layout control — можно задавать, где именно должны быть элементы;
🟡 веса доступны на Hugging Face, код — на GitHub;
🟡 модель уже работает на сайте Ideogram и через API.
По локальному запуску:
🟡 есть две версии: nf4 и fp8;
🟡 nf4 — CUDA-only, то есть в первую очередь для NVIDIA GPU;
🟡 сами веса nf4 занимают примерно 15 GB, поэтому для нормального локального запуска я бы ориентировался минимум на 24 GB VRAM;
🟡 16 GB VRAM может быть слишком впритык, особенно на высоких разрешениях;
🟡 версия fp8 весит примерно 25–26 GB, так что там уже логичнее смотреть в сторону 32 GB+ VRAM / RAM;
🟡 на Mac / CPU теоретически можно через fp8, но это уже скорее “запустить ради эксперимента”, а не комфортно генерировать.
По бенчмаркам Ideogram заявляет, что 4.0 — лучший open-weight image model на дизайне. В Design Arena он уступает только закрытым моделям от гигантов вроде GPT/Gemini, но среди открытых моделей идёт первым.
Важный нюанс: это не совсем “свободная open-source модель без условий”. Веса открыты, но лицензия у моделей — Ideogram 4 Non-Commercial, плюс доступ на Hugging Face gated. То есть для экспериментов, ресерча и локальных тестов — круто, но для коммерческого использования нужно внимательно смотреть условия.
GitHub: https://github.com/ideogram-oss/ideogram4
Модели: https://huggingface.co/collections/ideogram-ai/ideogram-4
Анонс: https://ideogram.ai/news/ideogram-4.0/
🤑 ForgetMe | Boosty
Приобрести подписку на любые сервисы
⏩ @forgetshop_bot
#нейросети #новости #ideogram

🔥
4
❤
2
👍
2