Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «CodeCamp»

CodeCamp
8.6K
2.1K
3.9K
2.3K
877.1K
Канал, который читает твой сеньйор.
Здесь про разработку, технологии и гаджеты 🤘
Редакция: @camprobot
Сотрудничество: @todaycast
РКН: https://clck.ru/3FjTpV
Здесь про разработку, технологии и гаджеты 🤘
Редакция: @camprobot
Сотрудничество: @todaycast
РКН: https://clck.ru/3FjTpV
Подписчики
Всего
183 639
Сегодня
0
Просмотров на пост
Всего
23 013
ER
Общий
9.7%
Суточный
8.4%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 8 649 постов
Смотреть все посты
Пост от 03.08.2026 09:23
3 138
0
128
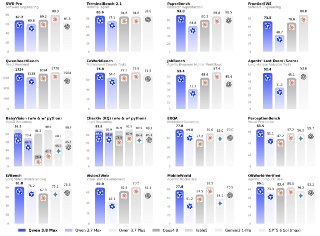
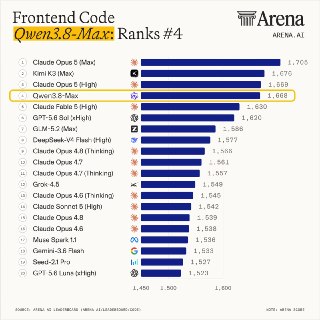
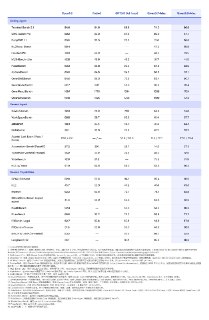
Китайцы выпустили мощнейшего конкурента Fable и GPT-5.6 Sol — Qwen 3.8 Max 😳
Главное:
— Это MoE-модель на 2,4 трлн параметров, которая может автономно работать больше 16 дней без перерыва и вмешательства человека.
— По бенчмаркам она чертовски хорошая и уже обходит GPT-5.6 Sol, Opus 4.8 и даже Fable в ряде задач. Так, во Frontend Code Arena она уверенно обогнала Fable.
— API при этом стоит $2 за миллион входных токенов, $6 — за выходные и $0,25 — за кэшированные входные, что почти в три раза дешевле Kimi K3.
— Уже на следующей неделе Alibaba откроет веса Qwen 3.8 Max и более компактной Qwen 3.8-27B.
Затестить можно уже сейчас тут, а блогпост посмотреть здесь. Праздник 🤩
Главное:
— Это MoE-модель на 2,4 трлн параметров, которая может автономно работать больше 16 дней без перерыва и вмешательства человека.
— По бенчмаркам она чертовски хорошая и уже обходит GPT-5.6 Sol, Opus 4.8 и даже Fable в ряде задач. Так, во Frontend Code Arena она уверенно обогнала Fable.
— API при этом стоит $2 за миллион входных токенов, $6 — за выходные и $0,25 — за кэшированные входные, что почти в три раза дешевле Kimi K3.
— Уже на следующей неделе Alibaba откроет веса Qwen 3.8 Max и более компактной Qwen 3.8-27B.
Затестить можно уже сейчас тут, а блогпост посмотреть здесь. Праздник 🤩

🔥
24
❤
9
😁
7
👍
3
Пост от 03.08.2026 01:10
1 245
0
125
Появилась коллекция скиллов, которые прокачивают ИИ до топового реверс-инженера 😎
Внутри reverse-skill 20 направлений и 80+ навыков для Claude Code, Cursor, Codex и других ИИ-агентов. С ними агент сам подбирает нужные инструменты и сценарии для реверса, анализа APK, CTF, поиска уязвимостей и исследований безопасности.
Проекты скажут вам спасибо 🙏
Внутри reverse-skill 20 направлений и 80+ навыков для Claude Code, Cursor, Codex и других ИИ-агентов. С ними агент сам подбирает нужные инструменты и сценарии для реверса, анализа APK, CTF, поиска уязвимостей и исследований безопасности.
Проекты скажут вам спасибо 🙏
Пост от 02.08.2026 11:46
3 180
0
122
Билл Гейтс выложил свой мини-список свежих книг, которые он рекомендует прочесть 🤓
Лучшая художественная литература: «Culpability» — это остросюжетный роман, посвященный моральной ответственности и этике в эпоху ИИ и беспилотных автомобилей;
Лучшая научно-популярная литература: «1929» Эндрю Росса Соркина — о биржевом крахе 1929 года и его последствиях;
Лучшая аудиокнига: «Gray Matters: A Biography of Brain Surgery» — научно-популярная книга нейрохирурга Теодора Х. Шварца о работе и мозге.
Читаем на выходных ☕️
Лучшая художественная литература: «Culpability» — это остросюжетный роман, посвященный моральной ответственности и этике в эпоху ИИ и беспилотных автомобилей;
Лучшая научно-популярная литература: «1929» Эндрю Росса Соркина — о биржевом крахе 1929 года и его последствиях;
Лучшая аудиокнига: «Gray Matters: A Biography of Brain Surgery» — научно-популярная книга нейрохирурга Теодора Х. Шварца о работе и мозге.
Читаем на выходных ☕️

❤
21
🔥
7
👍
4
😁
2
🌚
2
Пост от 02.08.2026 01:13
2 056
0
99
Y Combinator выложили в опенсорс свою платформу для ИИ-агентов 😨
QM — это агентный харнесс для команд: он умеет работать в Slack и браузере, подключаться к GitHub, Gmail и другим сервисам + поддерживает долговременную память и может выполнять несколько задач одновременно.
Для каждого сотрудника и проекта предусмотрено изолированное пространство для работы и три режима безопасности: Strict, Auto и Dangerous.
Забираем 😊
QM — это агентный харнесс для команд: он умеет работать в Slack и браузере, подключаться к GitHub, Gmail и другим сервисам + поддерживает долговременную память и может выполнять несколько задач одновременно.
Для каждого сотрудника и проекта предусмотрено изолированное пространство для работы и три режима безопасности: Strict, Auto и Dangerous.
Забираем 😊
🔥
9
👍
3
❤
2
🌚
1
Пост от 01.08.2026 09:55
2 037
0
69
Всё плохо: Google выпустил ИИ-фичу, которая не прожила и суток 😐
В Google Earth добавили генерацию изображений. По задумке — это позволило бы смотреть на одно и то же место в разных веках и обстоятельствах. Но пользователи сразу начали создавать фейковые авиакатастрофы, взрывы и природные катаклизмы. Так что Google уже на следующий день функцию просто отключили.
Кто бы мог подумать, что люди будут генерировать всякое 🤷♂️
В Google Earth добавили генерацию изображений. По задумке — это позволило бы смотреть на одно и то же место в разных веках и обстоятельствах. Но пользователи сразу начали создавать фейковые авиакатастрофы, взрывы и природные катаклизмы. Так что Google уже на следующий день функцию просто отключили.
Кто бы мог подумать, что люди будут генерировать всякое 🤷♂️

Пост от 01.08.2026 01:05
2 040
0
146
Ночное-полезное: принес вам трюк, который сэкономит вам кучу времени.
Если хотите быстро разобраться в репозитории, то замените в URL «github» на «gitdiagram» — так вы получите интерактивную карту проекта. Либо еще можете закинуть ссылку на репу сюда.
Пользуемся ☕️
Если хотите быстро разобраться в репозитории, то замените в URL «github» на «gitdiagram» — так вы получите интерактивную карту проекта. Либо еще можете закинуть ссылку на репу сюда.
Пользуемся ☕️
🔥
11
👍
3
Пост от 31.07.2026 20:12
2 778
0
60
Смотрим, создаём и запускаем что угодно прямо в терминале — нашёл локальный ИИ-комбайн для Mac с Apple Silicon и Linux
Бесплатный, нативный и локальный рантайм для, который закрывает вообще все задачи с нейросетями через один CLI:
Что умеет этот комбайн:
— Генерация текста и кода, создание картинок (Klein, ZImage), генерация видео (LTX, Wan 2.2), 3D-моделей (TRELLIS, InstantMesh), музыки и синтез речи (Qwen3 TTS);
— Из коробки доступны сегментация (SAM 3.1), OCR, детектор лиц, трекинг объектов и просчет карты глубин;
— Локальный API-сервер c OpenAI-совместимым эндпоинтом для подключения сторонних клиентов;
— Можно дообучать локальные LoRA-адаптеры под текст и графику;
— Автоматически проверяет объем памяти и возможности чипа перед загрузкой тяжелых моделей;
— Есть и нативное приложение на SwiftUI.
Яблочный спас 🍆
Бесплатный, нативный и локальный рантайм для, который закрывает вообще все задачи с нейросетями через один CLI:
Что умеет этот комбайн:
— Генерация текста и кода, создание картинок (Klein, ZImage), генерация видео (LTX, Wan 2.2), 3D-моделей (TRELLIS, InstantMesh), музыки и синтез речи (Qwen3 TTS);
— Из коробки доступны сегментация (SAM 3.1), OCR, детектор лиц, трекинг объектов и просчет карты глубин;
— Локальный API-сервер c OpenAI-совместимым эндпоинтом для подключения сторонних клиентов;
— Можно дообучать локальные LoRA-адаптеры под текст и графику;
— Автоматически проверяет объем памяти и возможности чипа перед загрузкой тяжелых моделей;
— Есть и нативное приложение на SwiftUI.
Яблочный спас 🍆
🔥
10
❤
5
👍
2