Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «Vibecoding Haven (BotfatherDEV)»

Vibecoding Haven (BotfatherDEV)
1.8K
13.1K
12
3
3.9K
Ділюсь про те як стати продуктивнішим використовуючи AI в програмуванні.
Подписчики
Всего
2 612
Сегодня
0
Просмотров на пост
Всего
411
ER
Общий
13.74%
Суточный
12.3%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 1 813 постов
Смотреть все посты
Пост от 01.08.2026 19:31
101
5
1
але дивно, що немає live voice mode

Пост от 01.08.2026 19:28
108
0
1
що він говорить сам про себе
просто постійний диск
мабуть і це добре
просто постійний диск
мабуть і це добре

Пост от 01.08.2026 19:13
135
29
0
я недооцінював chatgpt work
виявляється він працює без комп'ютера і підтримує скіли (чатгпт чат звичайний — не підтримує скіли)
хтось юзав вже, як вам?
виявляється він працює без комп'ютера і підтримує скіли (чатгпт чат звичайний — не підтримує скіли)
хтось юзав вже, як вам?
Пост от 01.08.2026 11:26
207
4
6
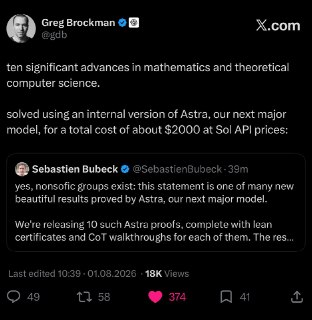
OpenAI готують нову модельку Astra.
Схоже, це їхня наступна велика модель, типу GPT-6.
І вона вже допомагає рухати математичні відкриття. На фоні всієї цієї jagged intelligence (коли модель вирішує надскладні задачі, але може провалитися на чомусь елементарному) поняття AGI взагалі поступово втрачає сенс 😮💨
Схоже, це їхня наступна велика модель, типу GPT-6.
І вона вже допомагає рухати математичні відкриття. На фоні всієї цієї jagged intelligence (коли модель вирішує надскладні задачі, але може провалитися на чомусь елементарному) поняття AGI взагалі поступово втрачає сенс 😮💨
Пост от 01.08.2026 08:49
121
1
2
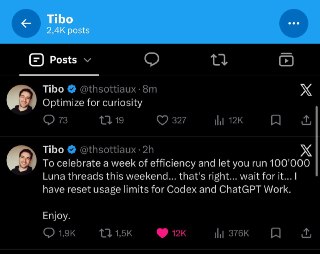
Схоже, що в них все пішло не по плану.
Але ліміти скинули 😏
Але ліміти скинули 😏
Пост от 31.07.2026 21:20
318
9
7
Актуалочка поки чекаємо на серебрас…

Пост от 31.07.2026 10:51
142
12
4
Увага! Сьогодні буде резет!
І дроп!
(і сподіваюсь 750тпс + нова підписка за 1000$)
І дроп!
(і сподіваюсь 750тпс + нова підписка за 1000$)
