Инструменты
Каталог TGAds
Мониторинг
Детальная статистика
Анализ аудитории
Бот аналитики
Полезная информация
Инструкция Telemetr
Документация к API
Чат Telemetr
Не попадитесь на накрученные каналы! Узнайте, не накручивает ли канал просмотры или
подписчиков
Проверить канал на накрутку


Телеграм канал «эйай ньюз»

эйай ньюз
3.6K
37.7K
4.8K
2.9K
194.0K
Культурно освещаю самые и не самые важные новости из мира AI, и облагораживаю их своим авторитетным профессиональным мнением.
Ex-Staff Research Scientist в Meta Generative AI. Сейчас CEO&Founder AI стартапа в Швейцарии.
Aвтор: @asanakoy
PR: @ssnowysnow
Ex-Staff Research Scientist в Meta Generative AI. Сейчас CEO&Founder AI стартапа в Швейцарии.
Aвтор: @asanakoy
PR: @ssnowysnow
Подписчики
Всего
93 278
Сегодня
-10
Просмотров на пост
Всего
28 740
ER
Общий
26.23%
Суточный
20.9%
Динамика публикаций

Telemetr - сервис глубокой аналитики
телеграм-каналов
телеграм-каналов

Получите подробную информацию о каждом канале
Отберите самые эффективные каналы для
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам
рекламных размещений, по приросту подписчиков,
ER, количеству просмотров на пост и другим метрикам

Анализируйте рекламные посты
и креативы
и креативы
Узнайте какие посты лучше сработали,
а какие хуже, даже если их давно удалили
а какие хуже, даже если их давно удалили

Оценивайте эффективность тематики и контента
Узнайте, какую тематику лучше не рекламировать
на канале, а какая зайдет на ура
на канале, а какая зайдет на ура

Показано 7 из 3 642 постов
Смотреть все посты
Пост от 20.05.2026 13:38
12 462
30
359
Как попасть на работу в Frontier AI Lab
Вышел хороший пост от чела из DeepMind про то, как попасть в frontier lab сегодня. Автор сейчас lead for Gemini pretraining в GDM, а до этого дропнулся с PhD и пошел в стартап Sisu, где быстро стал Head of ML.
Суть поста коротко: если хочешь попасть в топовую AI-лабу, надо прокачивать mathematical maturity, жутко потеть во время универа (причем задрачивать без использования LLM), уметь очень хорошо кодить, и делать работу на “краях” LLM-стека – снизу kernels / inference / systems / quantization, сверху agents / rigorous evals / agentic loops. Не просто “поиграться с агентами”, а делать технически строгие эксперименты и показывать вклад, который реально нужен frontier labs.
В целом всё по делу, но мне кажется, что автор упускает несколько важных вещей.
Не весь интересный frontier-level research вне топ-лаб ограничивается разработкой кернелов, low-level оптимизациями LLM и написанием агентских врапперов.
И чтобы заниматься frontier research, не обязательно идти только в большие лабы типа OpenAI, Anthropic, Meta Superintelligence Labs или GDM.
Frontier-level research можно делать и в стартапах на более ранних стадиях. И часто там у вас будет в разы больше ownership, а рост по карьере и по скиллам будет намного быстрее.
Иронично, что сам автор как раз так и сделал: дропнулся с PhD, пошел в стартап, быстро стал Head of ML – и уже после этого попал в Google, причем сразу на Staff-level позицию.
В стартапах есть куча фундаментально интересных задач, где не нужны $100M+ бюджеты. Есть задачи, для которых достаточно “двузначных миллионов”, сильной команды и правильного технического фокуса.
А в бигтехе, если ты не Director+, ты часто просто взаимозаменяемый винтик, которому дают потрогать маленькую фичу в огромной системе. Ownership минимальный, scope ограничен, выбиться на следующий уровень очень и очень трудно. Большинство людей до Staff+ никогда в жизни так и не дорастают.
Да, стартапов, где реально сильная команда и где можно делать фундаментальные вещи, не так много. Но именно в такие стартапы можно попасть на восходящей траектории карьерного роста — когда у тебя еще нет крутого track record, который нужен, чтобы хотя бы пройти скрининг в топовую большую лабу, но видно как ты резко ускоряешься. (Именно такой принцип я и применяю, когда отбираю более молодых кандидатов к себе в стартап)
И там намного больше пространства для роста. Никто не будет искусственно ограничивать тебя в scope. Всё зависит от тебя: насколько ты готов ебашить, брать ответственность и тащить сложные куски.
Кстати, раз уж заговорили про стартапы: мы в GenPeach AI всегда рады пообщаться с выдающимися кандидатами на позицию AI Research Scientist. Это как раз роль про работу над foundation models - не “AI wrappers”, а pre-train и post-train своих large-scale моделей, O(PB) данные, SOTA ресерч по кастомным архитектурам и методам контроля генерации.
@ai_newz #карьера
Вышел хороший пост от чела из DeepMind про то, как попасть в frontier lab сегодня. Автор сейчас lead for Gemini pretraining в GDM, а до этого дропнулся с PhD и пошел в стартап Sisu, где быстро стал Head of ML.
Суть поста коротко: если хочешь попасть в топовую AI-лабу, надо прокачивать mathematical maturity, жутко потеть во время универа (причем задрачивать без использования LLM), уметь очень хорошо кодить, и делать работу на “краях” LLM-стека – снизу kernels / inference / systems / quantization, сверху agents / rigorous evals / agentic loops. Не просто “поиграться с агентами”, а делать технически строгие эксперименты и показывать вклад, который реально нужен frontier labs.
В целом всё по делу, но мне кажется, что автор упускает несколько важных вещей.
Не весь интересный frontier-level research вне топ-лаб ограничивается разработкой кернелов, low-level оптимизациями LLM и написанием агентских врапперов.
И чтобы заниматься frontier research, не обязательно идти только в большие лабы типа OpenAI, Anthropic, Meta Superintelligence Labs или GDM.
Frontier-level research можно делать и в стартапах на более ранних стадиях. И часто там у вас будет в разы больше ownership, а рост по карьере и по скиллам будет намного быстрее.
Иронично, что сам автор как раз так и сделал: дропнулся с PhD, пошел в стартап, быстро стал Head of ML – и уже после этого попал в Google, причем сразу на Staff-level позицию.
В стартапах есть куча фундаментально интересных задач, где не нужны $100M+ бюджеты. Есть задачи, для которых достаточно “двузначных миллионов”, сильной команды и правильного технического фокуса.
А в бигтехе, если ты не Director+, ты часто просто взаимозаменяемый винтик, которому дают потрогать маленькую фичу в огромной системе. Ownership минимальный, scope ограничен, выбиться на следующий уровень очень и очень трудно. Большинство людей до Staff+ никогда в жизни так и не дорастают.
Да, стартапов, где реально сильная команда и где можно делать фундаментальные вещи, не так много. Но именно в такие стартапы можно попасть на восходящей траектории карьерного роста — когда у тебя еще нет крутого track record, который нужен, чтобы хотя бы пройти скрининг в топовую большую лабу, но видно как ты резко ускоряешься. (Именно такой принцип я и применяю, когда отбираю более молодых кандидатов к себе в стартап)
И там намного больше пространства для роста. Никто не будет искусственно ограничивать тебя в scope. Всё зависит от тебя: насколько ты готов ебашить, брать ответственность и тащить сложные куски.
Кстати, раз уж заговорили про стартапы: мы в GenPeach AI всегда рады пообщаться с выдающимися кандидатами на позицию AI Research Scientist. Это как раз роль про работу над foundation models - не “AI wrappers”, а pre-train и post-train своих large-scale моделей, O(PB) данные, SOTA ресерч по кастомным архитектурам и методам контроля генерации.
@ai_newz #карьера

🔥
67
❤
31
👍
20
😁
12
❤🔥
3
🤯
3
🙏
2
🦄
2
Пост от 20.05.2026 12:37
15 492
0
224
Mira — AI-агент в Telegram
Хорошая альтернатива OpenClaw, которая работает из коробки. Под капотом — саб-агенты, поддержка 1000+ MCP-серверов и работа в групповых чатах.
Через Mira можно автоматизировать кучу всего:
– Ремайндеры и автономные задачи;
– Трейдинг и мониторинг рынков;
– Кастомных AI-ботов;
– Генерацию и автопостинг контента;
– Связки с Gmail, Calendar, Notion, GitHub и другим стеком.
Без настройки серверов, API и сложного сетапа.
#промо
Хорошая альтернатива OpenClaw, которая работает из коробки. Под капотом — саб-агенты, поддержка 1000+ MCP-серверов и работа в групповых чатах.
Через Mira можно автоматизировать кучу всего:
– Ремайндеры и автономные задачи;
– Трейдинг и мониторинг рынков;
– Кастомных AI-ботов;
– Генерацию и автопостинг контента;
– Связки с Gmail, Calendar, Notion, GitHub и другим стеком.
Без настройки серверов, API и сложного сетапа.
#промо
😁
129
❤
20
💔
13
👍
5
🤯
4
🦄
4
🔥
3
🫡
2
🙏
1
Пост от 19.05.2026 20:52
22 392
69
333
Вышла Gemini 3.5 Flash
Она заметно сильнее чем Gemini 3.1 Pro, но цены за токены выросли в 3 раза, с $0.5/$3 до $1.5/$9 за миллион токенов. 3.1 Pro, для сравнения, стоит $2/$12 за миллион токенов для контекстов меньше 200к. Насколько реально выросла стоимость за задачу по сравнению с прошлой Flash мы узнаем только с тестами.
Самое главное — Google серьёзно отнёсся к проблемам в агентности и особенно прокачал модель в этом. Как пример показали как Gemini 3.5 Flash написала за 12 часов небольшую ОС, которая может запустить Doom. Pro модель существует, её обещают завезти в следующем месяце, страшно какие там заломят цены.
@ai_newz
Она заметно сильнее чем Gemini 3.1 Pro, но цены за токены выросли в 3 раза, с $0.5/$3 до $1.5/$9 за миллион токенов. 3.1 Pro, для сравнения, стоит $2/$12 за миллион токенов для контекстов меньше 200к. Насколько реально выросла стоимость за задачу по сравнению с прошлой Flash мы узнаем только с тестами.
Самое главное — Google серьёзно отнёсся к проблемам в агентности и особенно прокачал модель в этом. Как пример показали как Gemini 3.5 Flash написала за 12 часов небольшую ОС, которая может запустить Doom. Pro модель существует, её обещают завезти в следующем месяце, страшно какие там заломят цены.
@ai_newz
❤
134
🔥
56
🤯
33
👍
15
😁
4
🤩
1
💔
1
Пост от 19.05.2026 20:11
19 713
20
103
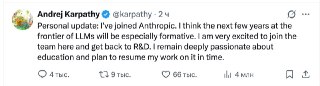
В одном из своих интервью осенью (кстати, очень рекомендую к просмотру) Адрей Карпатый говорил, что у него сформировалось FOMO, пока он был на вольных хлебах. Поэтому он, возможно, хотел бы вернуться назад в какую-нибудь frontier лабу в ближайшее время.
Ну, и вот, он уже в Anthropic!
@ai_newz
Ну, и вот, он уже в Anthropic!
@ai_newz
❤
180
🦄
51
👍
30
🤯
11
🔥
10
😁
3
💯
2
Пост от 19.05.2026 18:07
20 141
0
77
Главный навык на ближайшие годы — ВАЙБ-КОДИНГ
LLM уже пишут код, чинят баги, генерируют тесты, документацию и помогают запускать продукты в разы быстрее, чем это делали классические команды разработки. И это уже не "будущее когда-нибудь", а суровая реальность, которая меняет рынок прямо сейчас.
И те, кто научится вайбкодить сейчас, будут увереннее конкурировать на рынке и зарабатывать больше тех, кто по-прежнему хардокодит всё вручную (ну, по крайней мере, пока нас всех окончательно не заменят ИИ-агенты).
Стартовать с нуля поможет канал Вайб-кодинг. Там ребята круглосуточно мониторят более 320 российских и зарубежных источников и публикуют только главное: релизы, тулзы, гайды, курсы и практические кейсы.
Подписывайтесь, в комьюнити уже 45 тысяч: @vibecoding_tg
#промо
LLM уже пишут код, чинят баги, генерируют тесты, документацию и помогают запускать продукты в разы быстрее, чем это делали классические команды разработки. И это уже не "будущее когда-нибудь", а суровая реальность, которая меняет рынок прямо сейчас.
И те, кто научится вайбкодить сейчас, будут увереннее конкурировать на рынке и зарабатывать больше тех, кто по-прежнему хардокодит всё вручную (ну, по крайней мере, пока нас всех окончательно не заменят ИИ-агенты).
Стартовать с нуля поможет канал Вайб-кодинг. Там ребята круглосуточно мониторят более 320 российских и зарубежных источников и публикуют только главное: релизы, тулзы, гайды, курсы и практические кейсы.
Подписывайтесь, в комьюнити уже 45 тысяч: @vibecoding_tg
#промо

😁
228
❤
18
🤯
13
🫡
10
💔
5
🦄
5
👍
4
🔥
2
🤩
2
😱
1
Пост от 19.05.2026 07:28
22 511
43
117
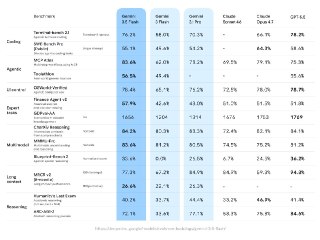
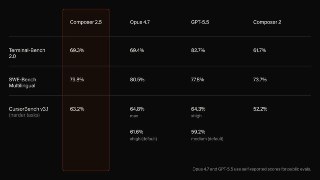
Cursor выпустили Composer 2.5
За два месяца модель заметно прокачали по бенчам, используя ту же базу K2.5. Количество синтетических тасков на которых тренировали модель увеличили в 25 раз. Это первая модель Cursor, натренированная в датацентрах SpaceXAI, они уже совместно тренируют заметно большую модель, используя в 10 раз больше компьюта. Скорее всего от результатов этой модели и будет зависить приобретёт ли SpaceX Cursor или нет.
С выходом новой модели удвоили стоимость fast mode, который включен по дефолту, теперь он стоит $3/$15 за миллион токенов, что равно стоимости Sonnet. Цена обычного режима не изменилась — $0.5/$2.5.
Блогпост
@ai_newz
За два месяца модель заметно прокачали по бенчам, используя ту же базу K2.5. Количество синтетических тасков на которых тренировали модель увеличили в 25 раз. Это первая модель Cursor, натренированная в датацентрах SpaceXAI, они уже совместно тренируют заметно большую модель, используя в 10 раз больше компьюта. Скорее всего от результатов этой модели и будет зависить приобретёт ли SpaceX Cursor или нет.
С выходом новой модели удвоили стоимость fast mode, который включен по дефолту, теперь он стоит $3/$15 за миллион токенов, что равно стоимости Sonnet. Цена обычного режима не изменилась — $0.5/$2.5.
Блогпост
@ai_newz
❤
71
🤯
24
👍
16
😁
8
🦄
8
Пост от 18.05.2026 15:11
25 323
78
455
В мире заканчиваются GPU
За последнее время сервера с GPU становится всё сложнее и сложнее арендовать, например прямо сейчас я не смог найти публичного провайдера, у которого можно арендовать даже 8xH100 (ну на васте есть еще пара машин), не говоря уже про кластер побольше. Да и даже одну единственную видеокарту стало сложно ухватить. A100 сейчас стоит дороже чем два года назад, видеокарта, на минуточку, уже почти шесть лет на рынке. На более новые видюхи цена тоже выросла в 1.5-2 раза.
Улучшения ситуации в ближайшее время не предвидится. Неоклауды не видят смысла сдавать GPU в аренду публично или на короткий срок, если всё и так купит антропик. А как вы решаете проблемы с компьютом?
@ai_newz
За последнее время сервера с GPU становится всё сложнее и сложнее арендовать, например прямо сейчас я не смог найти публичного провайдера, у которого можно арендовать даже 8xH100 (ну на васте есть еще пара машин), не говоря уже про кластер побольше. Да и даже одну единственную видеокарту стало сложно ухватить. A100 сейчас стоит дороже чем два года назад, видеокарта, на минуточку, уже почти шесть лет на рынке. На более новые видюхи цена тоже выросла в 1.5-2 раза.
Улучшения ситуации в ближайшее время не предвидится. Неоклауды не видят смысла сдавать GPU в аренду публично или на короткий срок, если всё и так купит антропик. А как вы решаете проблемы с компьютом?
@ai_newz
🤯
233
🫡
44
😱
33
❤
17
💔
8
👍
5
😁
5
💯
5
🙏
1